
こんにちは。freee の SRE チームに所属している nkgw (X) です。
KubeCon + CloudNativeCon Japan 2025 参加レポート 3日目を担当します。
先日開催された KubeCon + CloudNativeCon Japan 2025、楽しかったですね。 その中でも特に興味があった下記のセッションについて共有したいと思います。
From ECS To Kubernetes (and Sometimes Back Again): A Pragmatist's Guide To Migration
概要
本セッションは、オンラインで使えるグラフィックデザインツールである Canva が Amazon ECS (以降 ECS と表記) から EKS (Kubernetes) へとどのようなプロセスを経て移行したのかをお話されていました。
「なぜ ECS より EKS (Kubernetes) が良いのか」という技術比較よりも、「すでに動いている巨大なサービスを、どうやって安全に、現実的に移行していくか」という、実践的な戦略に焦点を当てた内容です。
私達も今まさに ECS 上で動いてるプロダクトを EKS で移行しようとしているのでタイムリーなセッションでした。
この EKS への移行で Canva は以下の Villain (乗り越えるべき大きな壁) と Lesson (得られた教訓) があったとのことだったので詳しく見ていきたいと思います。
Villain 1: スケーリング

Canva が移行で直面した最大の課題は、巨大なトラフィックを支えるスケーリングでした。
特に、ECS で動いていた既存のスケーリングロジックを、Kubernetes の世界でどう実現するかが大きな焦点となりました。
HPA(Horizontal Pod Autoscaler)の課題
Kubernetes のメジャーなスケーリングである HPA で複数のメトリクス(例:CPU使用率とメモリ使用率)を組み合わせてスケーリングすることも可能ですが、設定が複雑になりがちです。
また、更に大きな課題として、今までの CloudWatchMetrics をベースにした命令的なスケーリング(例:「もしCPUが80%を5分超えたら、2インスタンス追加する」)から宣言的なスケーリング(例:「平均CPU使用率が50%になるように維持する」)への思考モデルの転換が困難であった点とお話されてました。
KEDA (Kubernetes Event-driven Autoscaling)による解決
これらの課題を解決するために、Canva は KEDA を採用しました。KEDA は、SQS、RabbitMQ、Kafka など、HPA が標準では対応していない多様なイベントソースをトリガーに、Podを 0 から N までスケールさせることができるイベント駆動型のオートスケーラーです。
スライドに SQS Queue が多数記されたところから、SQS の Queue size をトリガーとした高速スケーリングを実現したかったのだと推測しています。 1 ただし Canva は、KEDA は救世主になるが、その挙動を正しく理解して使うことが重要である とも付け加えています。
Villain 2: 悩まされた「Eviction」問題

Canva は node autoscaler に Karpenter を採用しています。
Karpenter は非常に優れた binpacking 能力を持ち、コンテナをできるだけ隙間なくノードに詰め込むことで、使用するノード数を最小限に抑え、コストを最適化する技術です。
常にクラスタ全体を監視し、「よりコスト効率の良いノード構成がある」と判断すると、既存のノードを削除して Pod を新しいノードに集約・再配置しようとします。
この過程で、PodのEviction(強制退去)が発生するのですが、この課題に悩まされたそうです。
長い起動時間という弱点
Canva のワークロードの多くは Spring ベースであり、起動に時間がかかるという特性があるとのことです。
起動に時間が掛かると、もし Pod が Eviction された場合、Eviction はサービスの応答不可やパフォーマンス低下に直結してしまいます。
「Karpenter の絶え間ない binpacking 」と、「アプリケーションの起動の遅さ」この 2 つの組み合わせが、Canva にとって大きな課題でした。
Canvaの解決策:Kubernetes の標準機能を徹底活用
この課題に対し、Canva は特定の魔法のようなツールに頼るのではなく、Kubernetes が標準で提供する機能を徹底的に活用することで立ち向かいました。
特に、以下の 3 つのコンポーネントが不可欠であったと語られています。
PDB は Eviction などに対して、アプリケーションの Pod が最低何台、あるいは最大何台まで利用不能になってよいかを定義する仕組みです。
これを設定することで、「Karpenter が binpacking をしようとしても、アプリケーションの可用性を損なうほどの激しい Eviction は許可しない」という安全網を張ることができます。
Pod を複数の Node や Availability Zone に分散配置させるための制約です。 これにより、特定の Node に Pod が集中配置されるのを防ぎ、ある Node が終了対象となった場合の影響を限定的にすることができます。
Pod が本当にリクエストを受け付けられる状態になったかを、より厳密に判断するための仕組みです。
同じような仕組みとして Readiness Probe がありますが、これは アプリケーション自体が、リクエストを受け付けられる状態になったかをチェックする 役割に対して、Readiness Gates は Pod がトラフィックを受け取るために必要な、外部の条件が整ったかをチェックする 役割を持つものです。
起動に時間がかかるアプリケーションでも、完全にウォームアップが完了するまで Pod を Ready 状態にせず、安全にトラフィックを流し始めることができます。
これにより、Eviction のプロセス中に中途半端な状態でリクエストが送られてしまう事態を防ぐことができました。
Lesson 1: Capabilities analysis (能力分析)

Canva EKS 移行プロジェクトの根幹となる非常に重要なアプローチだなと感じました。
個々の対象サービスが EKS 移行に耐えうるものであるかではなく、サービスがプラットフォームに要求する能力に焦点を当てるという考え方です。
まず、すべてのサービスが必要とする能力を詳細にカタログ化し、各サービスがどのプラットフォーム能力に依存しているかをマッピングし、次に、その能力が各サービスに提供できていない箇所を洗い出した上で、「最も多くのワークロードの移行を可能にする能力」を優先開発する方針としました。
このアプローチは、プロジェクトの進め方に大きな変革をもたらしたそうで、特にマネジメント層との対話において、話の焦点が「サービスの移行進捗を示すバーンダウンチャート」から、「どれだけの能力を提供できたか、どれだけ迅速にその能力を提供できたか」にシフトしたそうです。
大規模な移行においては、個々のサービスに焦点を当てるよりも、基盤となるプラットフォームが提供すべき共通の能力を特定し、それらを体系的に整備していくことが、より効率的かつ効果的な戦略であったと説明されていました。
Lesson 2: Gain (real) confidence (本当の自信を得る)
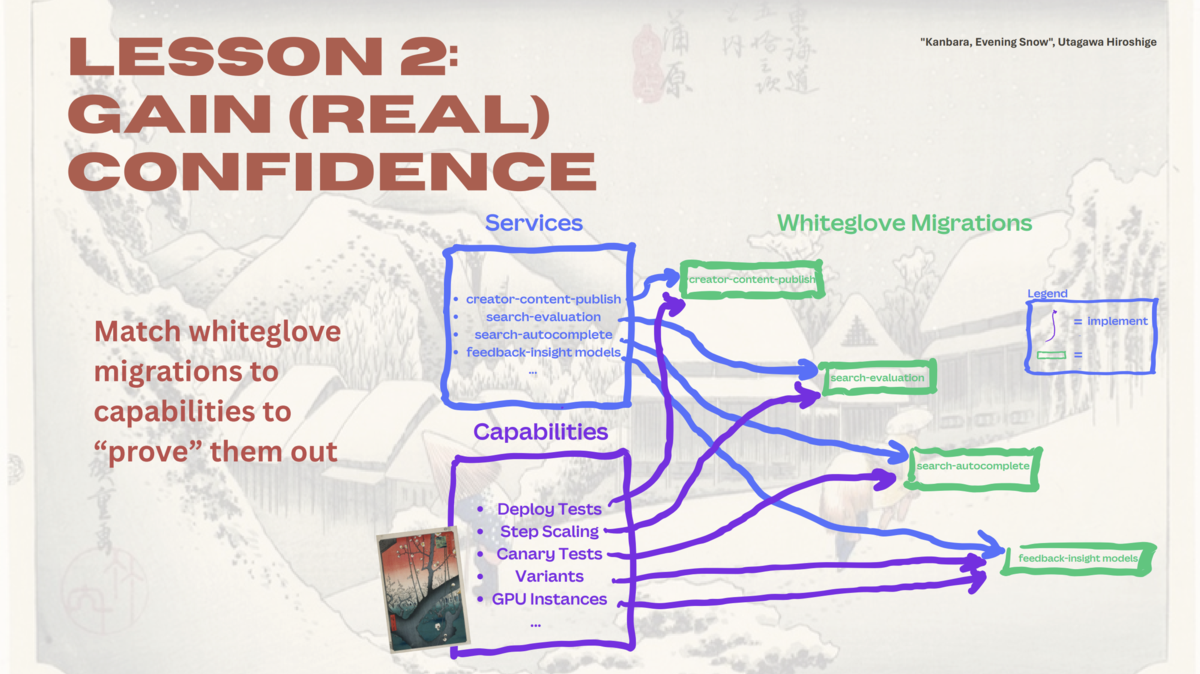
前述の「Lesson 1」で、各サービスがKubernetes を含むプラットフォームに要求する「能力(capability)」を特定しましたが、その能力すべてが全サービスを運用しきることができるものであるのか、 確証を得ながら進めるために以下のような具体的なアプローチが取られました。
まず影響範囲の少ないサービスを移行パイロット対象として選び、その移行を通じて、特定のプラットフォームが提供する能力が本番環境で「証明される」ことを目指しました。
一度移行が完了しプラットフォームの能力が証明されれば、それを利用するより多くのサービスの移行が可能になる、という戦略です。
また、Canva のプラットフォームチームは、プロダクトチームのリソースを損なわないように、彼らと緊密に協力し手厚いコンシェルジュのように移行を支援しました。
この Whiteglove Migrations は、Kubernetes への移行に対するプロダクトチームの心理的な抵抗感を和らげたとのことです。
Lesson 3: Have a Way Back(戻る道を用意する)
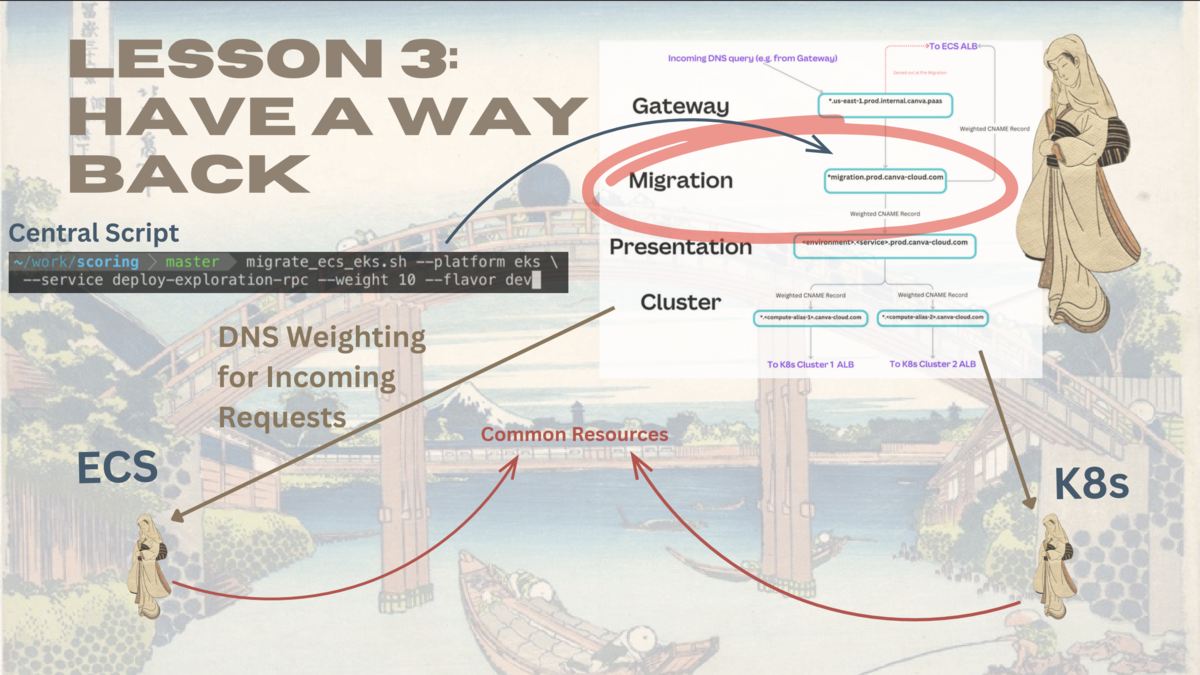
Canva は、Kubernetes への移行中に問題が発生した場合に、元のプラットフォーム(ECS)に安全かつ迅速に戻るための下記 4 つの戦略を構築しました。
これにより、何か問題があってもすぐに戻せるとして、プラットフォームチームとプロダクトチームは大きな自信を持って移行に臨むことできたそうです。
1. 両プラットフォームへの同時デプロイ
サービスを Kubernetes と ECS の両方のプラットフォームに同時にデプロイし、両方で稼働している状態を確保します。
同じアプリケーションイメージをそれぞれのプラットフォームにデプロイし、わずかな構成変更を適用するだけで、冗長性を持たせることができます。
2. トラフィックの分割・ルーティング
着信リクエストを ECS と Kubernetes の間で自由に振り分けるためには、DNS の加重ルーティングを採用したそうです。
これにより、新しいプラットフォームへ 10 %、20 % と徐々にトラフィックをシフトさせるカナリアリリースや、問題発生時にトラフィックを 100 % 元のプラットフォームへ戻す即時ロールバックが可能になりました。
Remote Procedure Call (RPC) のような内部通信についても、DNS の仕組みを活用し命令的に制御できるようにしました。
3. 共通リソースの利用
ECS と Kubernetes、両方の環境で稼働するサービスが、Database や Message Queue といった共通リソースを利用できるようにアーキテクチャを設計しました。
4. 非同期 Worker のルーティング
HTTPリクエストのような同期的なトラフィックだけでなく、Queu からメッセージを処理するような非同期 Worker もルーティング対象としたそうです。
例えば、kubectl や aws ecs コマンドを使って、移行元のプラットフォームのワーカーを 0 にスケールダウンさせます。
そうすると、Queue に溜まった Job は、移行先のプラットフォームで稼働している Worker に自然と流れることになります。
このような手段にて、非同期 Worker の処理能力もプラットフォーム間で自由に移動させました。
Lesson 4: When Ready, Migrate Quickly(準備ができたら、迅速に移行する)

プラットフォームへの信頼と安全性が確保された段階で、実際のサービス移行が始まります。
コホート(集団)による一斉移行
この段階では、個々のサービスを一つずつ移行するのではなく、準備が整ったサービス群を「コホート(Cohort)」と呼ばれる集団単位で、一斉に移行させます。
これにより、移行プロセスを大幅に加速させることができます。
移行パイプラインは、主に以下のフェーズで構成されています。
1. アクティブ移行 (Active Migration)
移行プロセスを自動化し、スムーズに進めるための準備段階です。
- 設定の自動生成
- 移行に必要な Kubernetes マニフェストなどを自動で生成します。
- 新旧両プラットフォームへの同時リリース
- アプリケーションの変更は、ECS と Kubernetesの両方に同時にリリースされます。
- 自動検証
- 開発環境での自動検証が行われます。
- ステージング検証
- プロダクトチーム自身によるステージング環境での最終検証も行われます。
2. ダークリリース (Dark Release)
これは、新しい Kubernetes プラットフォームと既存の ECS プラットフォームの両方にサービスをデプロイし、本番トラフィックを流す前の最終確認段階です。
この時点では、まだトラフィックは ECS に 100 %流れていますが、裏側では Kubernetes 上のサービスも本番として稼働しており、いつでも切り替えられる状態になっています。
3. トラフィックの自動切り替えとフォールバック
準備が整うと、トラフィックは徐々に Kubernetes にシフトされ、最終的には Kubernetes 上のアプリケーションが 100% リクエストを処理することになります。
しかし、これは片道切符ではなく、もし切り替え後に重大なインシデントが発生した場合には、すぐに ECS へトラフィックを戻すことができるフォールバックの仕組みが維持されています。
4. 移行後の保証期間 (Warranty Post-Migration)
サービスが Kubernetes に完全に移行された後も、2週間の「保証期間」が設けられます。
この期間中、ECSへのリリースは停止され、サービスはECSから削除されますが、万が一、後になって問題が発覚し、修正が困難な場合はロールバックできる状態が維持されます。
この 2 週間の保証期間を無事に終えたサービスが、晴れて完全に新しいプラットフォームへ移行したとみなされるとのです。
もちろん、この一連の移行プロセスは、常に成功するわけではありません。
チームの事情や技術的な問題により、あるサービスが移行を見送りたい場合、そのサービスはコホートから「退避(evicted)」され、ECS に留まることができます。
これにより、全体の移行の足を止めることなく、柔軟な対応が可能になっています。
Canvaの事例から学ぶ、freee の移行戦略との技術的なギャップ
Canvaのセッションは、大規模なサービスの基盤移行を成功に導くための学びが満載でしたが、私たちが進めている ECS から EKS への移行プロセスと比較すると、その実現方法において、いくつかの技術的な違いが見られました。
1. トラフィック移行戦略:「ALB Listener Rule」 vs 「DNS Weighting」
- Canvaのアプローチ
- 主に DNS Weighting を利用して、新旧プラットフォームへトラフィックを振り分けていました。
- これは、ドメイン名に対して CNAME を登録し、その重みを変更することでトラフィックを制御する方法です。
- freee のアプローチ
- 私たちのプロセスでは ALB の Listener Rule の重み付けを利用することを強く推奨しています。
- これは、ALB Listener 配下に、ECS と EKS それぞれに対応する Target Group をぶら下げ、その間のトラフィック比率を操作する方式です。
DNS ベースの切り替えではクライアント側の DNS Cache や既存のコネクションが原因で、トラフィックが即座に新環境へ切り替わらない問題が発生したことがあります。
このような問題を避けるため、サーバーサイドで確実かつ即座にトラフィックを制御できる ALB Listener Rule 方式を標準と定めました。
2. ヘルスチェックの標準化:「3つのパス」という規約
アプリケーションが正常であるかを判断するヘルスチェックは必要不可欠です。
- Canvaのアプローチ
- セッションでは、Pod Disruption Budgets や Custom Readiness Gates といった、可用性を高めるための大きな枠組みについては語られましたが、具体的なヘルスチェックエンドポイントの実装レベルまでには踏み込みませんでした。
- freee のアプローチ
- 私たちのプロセスでは、すべてのアプリケーションに対して、役割の異なる3つの標準エンドポイント(/live, /ready, /healthz)を実装することを強く推奨しています。
- /live コンテナのプロセスが生存しているかという、基本的な死活監視。
- /ready DBへのSELECTや外部サービスへの疎通確認など、全ての依存関係が正常であることを確認する厳密なチェック
- /healthz DBへのPingなど、サービス継続に最低限必要なクリティカルな依存関係のみを確認する緩やかなチェック
- 私たちのプロセスでは、すべてのアプリケーションに対して、役割の異なる3つの標準エンドポイント(/live, /ready, /healthz)を実装することを強く推奨しています。
詳しくは下記記事を併せて参照ください。
これらの技術的なアプローチの違いは、どちらが優れているという話ではなく、Canva が直面した課題と、我々が目指す全社的な技術標準という、異なるコンテキストから生まれた、それぞれに最適なアプローチなのだと感じました。
弊社の ECS -> EKS 移行プロセスを経て学んだノウハウについても、どこかでお話したいと思います。
最後に
KubeCon は動画で存在は知っていましたが、今回現地参加し Kubernetes に関わる様々な方が参加して非常に面白かったです。 この Canva の事例を始めは、自分たちの状況を客観的に分析し、最適な移行戦略を組み立てる上で、非常に多くのヒントを与えてくれる素晴らしいセッションだらけで非常に学びのある2日間だったと感じました。
- Datadog などでも実現は可能ですが、遅延が乗りやすいです。cf. クラウドメトリクスの遅延↩