
こんにちは。freee の Platform Solution チーム1 に所属している nkgw (Twitter) です。 この記事は freee 基盤チーム Advent Calendar 2023 の 15 日目の記事となります。 普段は、エンジニアリングマネージャーをしつつ、新規プロダクトのリリースサポートとか、プロダクトのキャパシティプランニングやコンピューティングリソース調整などをやってました。
今回、freee のプロダクトにおける health check の標準化について取り組みました。health check の要件と非標準化がもたらす具体的な問題を整理しつつ、freee では実際にはどのように health check を定義したのかを紹介します。
その前に...
詳細な内容の前に、弊社のような複数のプロダクトが相互に依存関係があるような環境下における health check の種類と要件について改めて整理したいと思います。
health check に求められる要件
health check とは、システムやサービスが正常に動作しているかどうかを確認するプロセスです。 これには、サーバー、アプリケーション、データベースなど、システムの重要なコンポーネントの状態を定期的にチェックする作業が含まれます。
AWS の builders-library にも同じような記述があります。
ヘルスチェックは、特定のサーバー上のサービスに、作業を正常に実行できるかどうかを確認する方法です。ロードバランサーは、各サーバーにこの質問を定期的に行い、トラフィックを転送しても安全なサーバーを判断します。キューからメッセージをポーリングするサービスは、キューからさらに作業をポーリングすることを決定する前に、自身が正常であるかどうかを自問する場合があります。モニタリングエージェント (各サーバーまたは外部モニタリングフリートで実行) は、サーバーが正常であるかどうかを確認して、アラームを発したり、障害が発生したサーバーに自動的に対処したりすることができます。
上記からシステム全体の構成を把握することが不可欠なため、概要構成を図式化しました。

構成は至ってシンプルでクライアントからのリクエストを AWS Application LoadBalancer が受け取り、紐付けられた target となる EC2 インスタンス内のアプリケーションコンテナへ処理が振り分けられる方式です。 強いて言えば、アプリケーション pod の前に envoy がいたり、プロダクト間で依存関係があったりする点でしょうか。
この構成上で health check が行われている箇所について深掘りをしていきます。
これまでの freee の health check の整理
区間 1 "ALB からの health check"

ALB は登録されているターゲットのうち、問題がある EC2 instance をターゲットから外す目的で ALB から EC2 instance に対して health check を送信しています。
また、freee ではアプリケーション pod の front に envoy が存在していますが、その設定ファイルには envoy.health_check のパラメータ pass_through_mode が false で設定されています。
指定条件にマッチしたリクエストはアプリケーション pod まで届かず、envoy が 200 or 503 を返すという設定になります。
これは、大量に増える health check をアプリケーションで捌くのではなく、envoy で打ち返すことで、アプリケーションのリソースを有効に活用しようとした目的で設定されています。
そのため、health check に応答するのは front envoy になります。
{ "name": "envoy.health_check", "typed_config": { "@type": "type.googleapis.com/envoy.extensions.filters.http.health_check.v3.HealthCheck", "pass_through_mode": false, <<< "headers": [ { "name": ":path", "exact_match": "/hogehoge" } ] } }
また envoy は、後述の envoy cluster health check の結果、cluster_min_healthy_percentages で指定された値以上だったら 200 を返すという動きになります。
これにより、envoy から先の pod が死んでる場合は、ALB には healthy だと伝えないようになり切り離されます。
message HealthCheck { ~snip~ // If operating in non-pass-through mode, specifies a set of upstream cluster // names and the minimum percentage of servers in each of those clusters that // must be healthy or degraded in order for the filter to return a 200. // // .. note:: // // This value is interpreted as an integer by truncating, so 12.50% will be calculated // as if it were 12%. map<string, type.v3.Percent> cluster_min_healthy_percentages = 4; <<< // Specifies a set of health check request headers to match on. The health check filter will // check a request’s headers against all the specified headers. To specify the health check // endpoint, set the ``:path`` header to match on. repeated config.route.v3.HeaderMatcher headers = 5; }
一方 gRPC (http2) を採用したプロダクトの場合は少し違い、ALB からの health check には gRPC が使われるようになります。
envoy で gRPC の health check を返す機能は見つからなかったため下図のように ALB からの health check を返すのはアプリケーション pod としています。

区間2 "kubelet からの health check"

これは Kubernetes の Readiness Probe / Liveness Probeが該当します。
ALB 同様、Kubernetes Service というコンテナ外からリクエストを受け付ける機能から 、問題がある pod をターゲットから外す目的で kubelet2 から pod に対して health check を送信しています。 ここでアプリケーションで実装した health check 向けエンドポイントが叩かれ、DB などの重要なコンポーネントへのチェックも行われます。
{ ~snip~ "livenessProbe": { "failureThreshold": 10, "httpGet": { "path": "/live", "port": 3000, "scheme": "HTTP" }, "initialDelaySeconds": 30, "periodSeconds": 10, "successThreshold": 1, "timeoutSeconds": 60 }, "readinessProbe": { "failureThreshold": 10, "httpGet": { "path": "/ready", "port": 3000, "scheme": "HTTP" }, "initialDelaySeconds": 30, "periodSeconds": 10, "successThreshold": 1, "timeoutSeconds": 10 }, ~snip~ }
gRPC も Rails も、この区間の health check は どちらも http1.1 を使って health check を行います。3
区間 3 "envoy からの cluster health check"

前述区間でちょっと触れました Envoy が行う cluster health check です。
ALB や Kubernets Service と同じく問題のある upstream cluster をターゲットから外すという目的は同じですが、チェックする対象が利用するプロトコルによって違ってきます。
Rails (http1.1) の場合
この場合、Kubernetes Service は ClusterIP を採用しています。 envoy は ClusterIP の FQDN のアドレスを問い合わせますが、その時返却されるアドレスは一つになります。
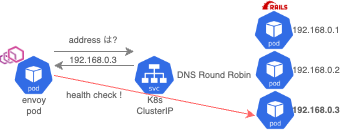
そのため、envoy からの cluster health check の宛先は pod 群の一つに送られてチェックされます。
envoy clusters endpoint を叩くと stats が 1 台分しか返ってこないことがわかります。
hogehoge::172.20.239.61:3000::hostname::hogehoge.fuga.svc.cluster.local hogehoge::172.20.239.61:3000::health_flags::healthy
gRPC (http2) の場合
この場合、Kubernetes Service は Headless Service を採用しています。 envoy は Headless Service の FQDN のアドレスを問い合わせますが、その時返却されるアドレスは紐づく pod すべてになります。
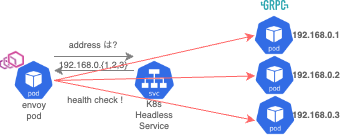
そのため、envoy からの cluster health check の宛先は pod 群全部に送られてチェックされます。
同じく envoy clusters endpoint を叩くと stats が 紐づく pod 台数分の情報が返ってきます。 無邪気に health check の条件を厳しくすると、めちゃめちゃ health check endpoint が叩かれることが用意に想像できますね...
hogehoge::10.101.46.142:30000::hostname::hogehoge.fuga.svc.cluster.local hogehoge::10.101.46.142:30000::health_flags::healthy hogehoge::10.101.73.214:30000::hostname::hogehoge.fuga.svc.cluster.local hogehoge::10.101.73.214:30000::health_flags::healthy hogehoge::10.101.159.254:30000::hostname::hogehoge.fuga.svc.cluster.local hogehoge::10.101.159.254:30000::health_flags::healthy hogehoge::10.101.37.145:30000::hostname::hogehoge.fuga.svc.cluster.local hogehoge::10.101.37.145:30000::health_flags::healthy
区間4 "プロダクト外からの health check"

これは、今までの health check とはちょっと毛色が違い、システム障害の早期検知のための外形監視だったり、依存関係のある重大な別プロダクトが障害の場合はユーザーにサービスを提供できないようにする目的で使われます。
以上から、health check が様々な目的で異なる箇所に適用されていることが明らかになりました。
非標準化がもたらす問題点
この多様性は、health check の非標準化につながり、以下に挙げるような複数の問題を引き起こしています。
問題1: 外形監視がアプリケーション Pod まで届いてなかった問題

1つ目は上記の図のように、アプリケーションが用意した health check 用途の path と、envoy の health check path を同一としてしまったケースです。
この状態で health check path に向かって外形監視を行っても、envoy までしか監視リクエストが届かず、アプリケーションのステータスを監視できません。
問題2: health check path の不一致による運用の認知負荷増大問題
health check path の名前の不一致も大きな問題の一つです。
異なるプロダクトがそれぞれ異なる endpoint や path を health check に用いているため、システムの運用が非常に煩雑になっています。
たとえば、あるプロダクトは /monitor のみを使用し、別のプロダクトは /live と /ready を、また別のプロダクトでは /healthz を利用しているケースなど...
path 名からも推測できないバラバラな実装は、いざというときに高い認知負荷を産みます。
さらに、health check の用途と path 名が一致していないため、名前だけからはその path がどのような目的で使われているのか理解することが困難です。
このような状況は、システムの全体的な監視と運用の効率を低下させ、誤設定のリスクを高めています。
これらの問題を解決するために、freee では以下を標準構成とするように定義してみました。
freee における health check ベストプラクティス
目的と health check 内容に応じた health check path パターンを 3 つ定義しました。
アプリケーションのプロセスが生存しているかどうか確認するための path
これは Kubernetes の Liveness Probe によってのみ利用されるエンドポイントです。
- このエンドポイントが叩かれたときには、アプリケーションが http リクエストをさばけるプロセスが起動しているかどうかだけを確認するように定義しています。
- もちろん、プロダクト内でしか使われないのでプロダクトの外からは利用されません。
- 名前は生存確認目的であることがわかるように
/liveなどをつけてもらっています。
アプリケーションがリクエストを捌ける状態であるかを確認するための path
これは、Kubernetes の Readiness Probe、 Envoy cluster health check、ALB からの health check によって利用される path です。
- このエンドポイントが叩かれたときには、アプリケーションが http リクエストかどうか重要な各コンポーネントへのアクセスなどを確認するように定義しています。
- これも、プロダクト内でしか使われないのでプロダクトの外からは利用されません。
- 名前はルーティングの準備ができてるかどうかを確認する目的であることがわかるように
/readyなどをつけてもらっています。
プロダクトが利用可能であるか、プロダクトの外から確認するための path
これは、自分のプロダクト外から来るアクセスが叩きに来たり、外形監視などで利用されたりする path です。
- これは、プロダクト A が、依存するプロダクト B に対する health check を実施したい場合などで利用するようなイメージです。
- 基本的にプロダクト外からのアクセス目的のため、プロダクト内部でのチェックには使われません。
- 名前はプロダクトの health status 確認目的であることがわかるように
/healthzなどをつけてもらっています。
標準化導入によるメリット
この標準化を導入することで、以下のようなメリットが得られると期待しています。
- システムの安定性と信頼性の向上
- 運用コストの削減
- 迅速な問題解決とプロアクティブなメンテナンス
- 開発チームの生産性向上
さいごに
いかがでしたでしょうか。現在の freee と同じような課題感を持っている方々の一助になったらと思い記事にしてみました。
この取り組みは現在進行中なので、よりプロダクトチームの開発生産性を上げるような取り組みを進めていく予定です。
また、この記事にできなかった内容についてカジュアル面談などでぶっちゃけた話をしたいと思いますので、興味がある方はぜひお気軽にご連絡ください。
最後までご覧いただきありがとうございました。
明日は oracle2k さんの AWS コストに関する記事です!お楽しみに!