
こんにちは。freee の Enabling SRE チームに所属している nkgw (Twitter) です。
freee Developers Advent Calendar 2022 の 15 日目の記事となります。 普段は、エンジニアリングマネージャーをしつつ、新規プロダクトのリリースサポートとか、envoy の機能である external authorization の実装などをやってました。
以前 SRE チームのマネジャー 河村より 2022: freee SRE Journey - これまでの振り返りとこれから という記事にて今までの SRE チームの遍歴及び簡単な今後について書いていただきました。 本記事では freee の SRE の Rebuild として、どのようにプロダクトチームと一緒に SRE の Enabling(有効化) を進めていくのか、プロダクトチームが SRE を実践している状態とはどのような状態なのか?を定義したという話をしたいと思います。
前提
SRE は立場や視点次第で色々なコンテキストを持つ用語になります。そのため、この記事では独断と偏見で下記と定義しました。1
| 言葉 | 定義 |
|---|---|
| SRE | Site Reliability Engineering. ロールではなく Googleが提唱2している機能を持つ文化と定義します。概念的なものを指します。 |
| SREs3 | 概念的なものではなく、ロールと定義。今までインフラの構築運用を行ってきたメンバーのロールです。文化の話なのかロールの話をしているのかわからなくなるので区別をつけるために定義しています。 |
| Product SREs | プロダクトチーム内で、SRE という文化を浸透させていくためにアサインされたメンバーのロールを指します。 |
| Stream Aligned team | 単一の価値ストリームに沿って動くチーム。freee のプロダクトチームはこれに該当します。 |
| Enabling SRE team | Stream Aligned team の能力ギャップを解消させるために動くチーム。主な役割は支援、サポートです。 |
| Platform SRE team | Steam Aligned team がサービス開発に関する認知負荷を下げるため、サービスを載せる基盤の横断的仕組み化を担うチーム。 |
SRE の Rebuild とは何?
これまでの中央集権的な SRE への依存を脱して、プロダクトチーム主体で運用までを担うセルフサービスチーム化を目指す、という考え方が主軸となっています。
今までの freee の SRE の遍歴や組織の課題感については前述の記事をご参照いただきたいと思うのですが、あえてサマらせていただくと...
- ユーザ価値を追い求めると、プロダクトチームが stream aligned としてソフトウェア開発ライフサイクルのアジリティを向上させることがプロダクトの進化とマジ価値につながるのではないかという仮説がある。
- その仮説の背景として、開発組織増大に伴い、オーバーヘッドとなる他チームとの連携が発生し、ソフトウェア開発ライフサイクルの一部がボトルネックとなってしまっている状況がある。
- 打破するために、過剰な他チームとの連携をなくしつつ(≒ 適正なチーム連携にする)、プロダクトチームが 自己完結型且つメトリクスドリブンで意思決定可能 な状態になることで、ソフトウェア開発ライフサイクルのアジリティを向上させる、つまりはプロダクトを進化させることができるのではないか。
というロジックのもと、変革していきたいというお話でした。
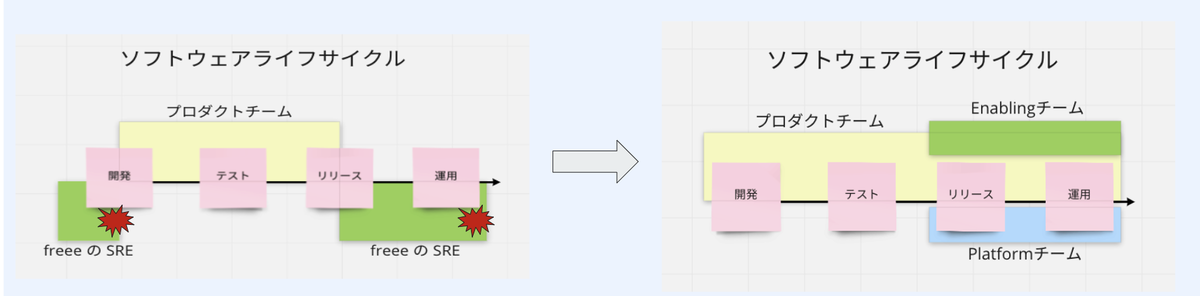
プロダクトチームに対する SRE Enabling のアプローチ
SRE の Rebuild の方針とともにプロダクトチームの中から Product SREs を担っていただける方をアサインいただけないかというお願いをした際に、出てきた質問の中に、短期的な課題感は理解できるものの、プロダクトチームに求める SRE の定義が無くイメージしづらいので判断がつかない という印象的な質問がありました。
コレは確かに仰るとおりで、プロダクトチームが SRE が実践できているとはどういう状態なのか を定義がない状態では、どのようなメンバーを Product SREs にアサインしたら良いのかわからないと思います。
他には、各チーム内にインフラ領域のスキルが足らずチームの外から採用しなければならないとなった場合にもどのようなスキルマップが求められるのかがわからないので、中長期の採用計画が立てられないといった悩みもあります。
更に、今までインフラ領域を freee の SREs で運用していて、freee SREs の事情に合わせた基盤や仕組みとなっていたり、ドキュメント類が成熟してない & メンテナンスができてないため、インフラのスキルがある方でも freee のインフラを一からキャッチアップするのしんどいよ... という声も聞こえています。
それはそうですね。プロダクトチームはインフラを作れるようになることがゴールではなく、インフラを駆使し価値あるプロダクトを作り出すことが求められているから本質的ではありません。
つまり、現在の freee において SRE プラクティスが実践できる土壌が整ってない状態です。そんな状態で SRE プラクティスを実践することに価値があるんだ!と言っても浸透しないだろうとなりました。
上記の事情を考慮し、 プロダクトチームが SRE を実践できている状態を仮定義してみました。 定義するにあたり、Google の Service Reliability Hierarchy4 をベースとして、freee の課題感を反映させました。

階層間は関連性があるため、まず基礎階層である Foundation & Monitoring を最優先で定義しています。 また、この記事の執筆時点では活動していくぞ!という段階のため、Product SREs の皆さんと一緒に議論しながら今の開発組織に最適なアプローチを適用していく予定です。 実際どうだったのかと言うのは、後日談としてどこかでお話させていただきます!
Foundation と Monitoring って何?
SRE 本からの抜粋になりますが、SRE とは システムの信頼性に焦点を置き、その性質を向上させるため、ソフトウェア・エンジニアリングを通じて設計と運用の改善方法を見つけること になります。
なので、定量的な判断を下せるユーザーの利用シナリオ (CUJ : Critical User Journey) に基づくメトリクスが重要なため、SRE 本では 7 階層の一番重要階層として Monitoring を定義されています。
一方 freee で SRE を実践するにあたり、一番の壁は、前述のとおり freee 基盤の理解、現状の把握、及び理想状態とのギャップの分析 という SRE プラクティスの実践の基礎となる部分ではないかと仮説を立てています。 長年 freee の SREs が運用しやすいように基盤を整えてきたという歴史的背景もあり、freee 基盤は一般的なクラウドやコンテナ技術を習得しているプロダクトチームのメンバーはもちろん、SREs に新しく join された方でもキャッチアップコストが大きい状態です。 また、ドキュメントが不足してたりメンテナンスできてなかったりしていて、freee のインフラを構築運用するため各種操作をしようとしたとき、どこに何があって、どの様に PR を作ればよいのか、何を気をつけるべきなのかが非常に解りにくい状態で、先人の PR だったり、メンターやチームメンバーからの口伝で凌いでいたりします。
仮にその壁を乗り越え、どの様に操作するのを理解したとしても、次に現れる壁として、理想状態が不明確であるという点があります。 今までもプロダクトをリリースするときに、freee SREs がインフラリリースチェックを行っていましたが、だれがチェックしても同じ状態になるとは言い難いものです。
運用のコスト低減の観点から Network ACL を使わない というような Yes or No で答えられるものなら良いのですが、選択肢が無限に考えられるような観点だと原則しか設けてないものがあります。
例えば、3AZ で冗長化されていることとあるが、その冗長化というのはどこまでか EKS ? LB ? DB ? 全部 ?といった感じで細かいチェック項目ではありません。
また、リリース後に機能追加のためインフラ構成を変更し、知らないうちにチェック項目から外れてしまっているといった変化に追従できていない点も問題です。
そのため、SRE を実践するための基礎状態を作ることが今の freee において重要であると考え、今回下記のように状態を定義してみました。
[Foundation] プロダクトに関して解像度を上げて、下記の状態にする
1-1. freee のインフラ基盤を使って、インフラを構築運用できる。
1-2. freee の標準プロダクト構成に基づき、同じものが作れる。
1-3. オーナープロダクトの状態を評価し Production Ready な状態であるのかが把握できている。
[Monitoring] CUJ ベースの Monitoring について、下記の状態にする
2-1. すべての指標となる CUJ ベースでの SLO を策定、その値が意思決定に使われるような振り返りが行われている。
2-2. メトリクスベースでのアラートから SLO ベースでのアラートになっている。
2-3. プロダクトチーム内で アラート体制や通知設計が行われており、ノウハウが溜まっている。
その状態になるのは難しいのでレベルごとにグラデーションを付けたのが下記になります。
Product SREs 成熟度 レベル
CNCFの成熟度レベルに倣い、Sandbox、Incubating、Graduated と定義しました。
Incubating から Graduated になったものはキャズムを越えると定義している点もマッチしていそうです。

画像引用元. https://www.cncf.io/projects/
Sandbox
- ☑ 開発リソースの一部を SRE 実践に充てるという意思決定を行っていること。
プロダクトチームに SRE を実践してもらうためには、プロダクトに SRE 実践させるため、リソースを割いていただく必要があります。 理想を言えば、SRE を実践するためのハードルが低く、特に意識をせずとも SRE プラクティスが行われている状態ではあるのですが、短期〜中期ではまだまだそのフェーズには到達できそうにありません...
また、プロダクト構成の標準化など SREs が肩代わりを行い、土壌ができてから引き渡すという案もありますが、その仕組み自体のキャッチアップコストが大きいので、Sandbox ステージでは、freee SREs とプロダクトチームが一緒になって、理解を深め標準化を進めていく というのがとても重要だと考えています。 もちろん、デメリットもあります。プロダクト開発のためのリソースを SRE 実践に割り当てるので当然開発速度は落ちます。そんなデメリットを可能な限り軽減させるために、Enabling SRE が存在しております。
それを上回る プロダクトチームにとっては将来的に、stream aligned になることで、ソフトウェア開発ライフサイクルが自己完結化できるようになるし, アサインされた方のエンジニアのキャリアとしても、production ready な Kubernetes 環境で SRE プラクティスの実践を行うというのは非常に有益である といったメリットもあります。
ですので、プロダクトチームから Product SREs をアサインして、日々の開発業務の数十% をこの Enabling にリソースを割いていただく意思決定をしていただきます。
- ☑ freee のプラットフォームについて知っていること。
前述しているとおり、インフラ周りの知見がある方でも、freee のインフラ難しいというお話を聞くことがあります。 わかります、私もそうでした。
freee で採用しているインフラ技術は、AWS / Kubernetes を中心に多岐に及びますが、実はプロダクトを構築し、日々運用するという点だけに着目すると、AWS / Kubernetes スペシャリスト5である必要はありません。 もちろん、対象技術の知見を深く知っているに越したことはありませんし、キャッチアップ速度が加速することは確実です。
ですが、その中でも極一部の知識があれば最低限手を動かし運用することは可能です。 例を上げるとしたら、AWS EC2 を起動する細かいオプションまで把握しておく必要はありませんが、外から接続するために Security Group でコントロールしており、どこを変更すれば対象を追加できるか?とか、S3 などのリソースを操作するためには IAM policy のどこを変更すればよいのかなどです。
ということで、プロダクトチームの方には、それをキャッチアップしていただくことを考えています。 具体的には、Product SRE プログラムでは、既に用意している Kubernetes クラスタの上に、用意したサンプルイメージを使ってサービスを構築し、外から接続できるようにしてもらうもので、SRE メンバーがオンボーディングに利用しているプログラムの中から、よりプロダクト構築及び運用にのみフォーカスしたものをイメージしています。 最後に、サービス構築時に必要な設計の知識について簡単なテストを受けてもらい、クリアしたら各種リソースを操作できるような強い権限をお渡しします。
- ☑ freee プロダクトの現状を知っていること。
我々は SRE プラクティスを実践するには属人化があってはならないと感じています。 属人化してしまうとただ単にボトルネックがプロダクトチーム内に移るだけで、組織がスケールしない状態になります。 また、現在のプロダクトの状態を調査し、理想状態とどれだけ差分があるのかを把握することも大事であると考えています。
細かい実際の内容については各プロダクトごとに差異がありますが、我々が考えているのは そのプロダクトは production ready な状態を保っているのかと freee 標準構成に準じているかの 2 点です。 現在、上記の2点はそれぞれ freee production readiness check list と freee cloud design pattern というもので定義することを始めています。 詳細な取り組みについては別途どこかでアウトプットさせていただきたいと思ってます。
上記を行うことで、今のプロダクトの理解が進み、理想状態とどれだけ乖離があるのか、また優先順位は何なのかというものが明確になります。
- ☑ ロードマップの決定が決まっていること。
今までの項目で現状と理想状態の差分が明確になり、優先順位も明確になるので、いつまでに何をやるのかいうロードマップを引くことができるようになります。 これでようやくスタートラインに立てました。
Enabling SREs と Product SREs のチームインタラクション
文字だけだと実際にどのように進めていくのかあまりイメージしづらいと感じているので、Team Topologies に則りチームインタラクションを定義していきたいと思います。 この Sandbox ステージでは、プロダクトチームのリソースを一部借りつつ、プログラムの実施、構成の理解などを無駄なく迅速に実施する必要があります。
これは素早く次のステージに進めたいという意図もありますが、一番は本来機能開発するためのリソースをせっかく割いて頂いているため無駄なく進めたいという想いがあります。 なので、よりプロダクトチームに近い場所でコミュニケーションをする必要があるのではと考えています。
上記より Enabling SRE と プロダクトチームコラボレーションというチームインタラクションを想定しています。

Incubating
Incubating ステージでは前のステージで洗い出した課題のロードマップに従い、改善や新サービスの構築などを行います。 そのため、下記のような状態を目指します。
- ☑ プロダクトの構成標準化と独自進化の改善
- ☑ CUJ ベースでの SLO 策定運用
- ☑ SLO を駆使した Monitoring の適正化
Enabling SREs と Product SREs のチームインタラクション
このステージでは、チームで確保できる Product SREs のキャッチアップ状況やスキルセット、そのプロダクトが持つビジネスに対してもつ重要度、そのプロダクトの治安状態によってチームインタラクションを柔軟に変えることを想定しています。


Graduated
ここまで来たら、後は横展開です。
すでにチームは stream aligned な状態ではありますが、現状はアサインされた Product SREs の方にリソースに依存してしまいます。Product SREs がボトルネックになってしまったら stream aligned ではありません。 プロダクトチームメンバー全員ができるようになっていることが理想です。が、プロダクトチーム全員に Product SREs と全く同じレベルを求めるというのは少しずれているかと思います。
ここまでの取り組みで Product SREs が SRE を実践するのに必要なスキル感とそうではないスキルが明確になってきているかと思います。 現時点で私が思い描いている プロダクトチームメンバーと Product SREs の境界線は、プロダクトの理想状態を把握しているか否かの点ではないかと考えています。
プロダクトチームメンバーは freee のインフラ基盤を利用して新しいプロダクトを作ろうと PR を出すことは可能だが、理想状態は把握してないので、Product SREs にレビューしてもらうというイメージです。[^5] また、Monitoring についてはプロダクトチーム全体で SRE が浸透している必要があるため、下記 2 点を定義しました。
- ☑ プロダクトチームメンバー全員が freee のインフラ基盤について理解し、プロダクト構成も把握できている状態
- ☑ プロダクトチームに SRE が浸透してプロダクトチーム主導で Monitoring のSRE プラクティスを実践できるようになっている状態
Enabling SREs と Product SREs のチームインタラクション
このステージでは、Product SREs がオーナプロダクトに対して SRE を実践しつつ、プロダクトチーム主導で SLO 運用が行える状態を想定しています。これにより、Monitoring 面ではプロダクトチームは stream aligned になっています。 また、現状の仕組みでは、プロダクトチーム内の開発者のキャッチアップコストが大きく、改修するべき点について Enabling SREs へフィードバックする文化ができている XaaS なインタラクションを想定しています。

また、ここまで記載したのはあくまで Fundation & Monitoring 階層までで、上位階層の実践指標を定義したら再び Sandbox から進めていくことを想定しています。 Enabling SRE は表にすると下記のように進んでいくイメージです。
| product | Fundation / Monitoring | Incident Response | Postmortem / Root Cause analysis | Testing + Release procedures | Capacity Planning | Development | Product |
|---|---|---|---|---|---|---|---|
| サービス A | Graduated | Graduated | Sandbox | NotReady | NotReady | NotReady | NotReady |
| サービス B | Graduated | Sandbox | None | NotReady | NotReady | NotReady | NotReady |
| サービス C | Graduated | Incubating | None | NotReady | NotReady | NotReady | NotReady |
| サービス D | Sandbox | None | None | NotReady | NotReady | NotReady | NotReady | NotReady |
| サービス E | Graduated | Incubating | None | NotReady | NotReady | NotReady | NotReady | NotReady |
Enabling の副次的な効果
SRE を実践する上で下記のような効果もあるんじゃないかと見込んでます。
- 基盤や仕組みに対する Feedback により進化が可視化・加速する
- 新たな技術領域に対するチャレンジしやすい土壌ができる
とくに後者は、SLO といった指標が明確になり、チャレンジの余白が明確になります。例えば、puma vs passenger とか、cillium とか、service mesh とか... freee にとって有用であるにも関わらず、プロダクトがどの様に動いているのか不明でチャレンジしにくいとか導入しようと思っても既存サービスへの影響具合が可視化されていないのでチャレンジしづらいとかが少なくなります。(なるといいな。)
効果がある取り組みなのか?
freee には、一定期間別のチームに入り実際に業務を体験できる 留学制度 があります。
その制度を活用し、プロダクトの解像度を上げることで実際に Enabling SRE を進めることができた実績を積めたので一定の効果は期待できるものと信じています。
詳しくは ogugu の下記記事をご参照ください。
さいごに
いかがでしたでしょうか。現在の freee と同じような課題感を持っている方々の SRE プラクティス実践の一助になったらと思い記事にしてみました。 この取り組みは現在進行中なので、よりプロダクトチームが stream aligned になるように取り組んでいく予定です。 また、この記事にできなかった内容についてカジュアル面談などでぶっちゃけた話をしたいと思いますので、興味がある方はぜひお気軽にご連絡ください。
最後までご覧いただきありがとうございました 明日は naoya7076 さんの記事です! お楽しみに!
- この定義を決めるにあたり Team Topologies(チームトポロジー) の影響を多大に受けてます。↩
- システムの信頼性に焦点を置き、その性質を向上させるため、設計と運用の改善方法を見つけることとなります。↩
- CyberAgent さんの考え方が、非常にわかりやすかったので踏襲しています。↩
- Google SRE 本 に書かれている。システムがサービスとして機能するために必要な最も基本的な要件から、より高いレベルの機能まで、サービスの健全性を特徴付けた階層。↩
- 長期的には理想状態となるポリシーもコード化し、自動でチェックする Policy as Code のような仕組みも検討しています。↩