
この記事は、freee Developers Advent Calendar 2025 の 12日目の記事です。
こんにちは。freeeでエンジニアをしている高田と申します。普段はエンジニア横断組織で共通基盤・社内用共通ライブラリを開発したり、プロダクトの開発支援などを行っています。趣味はお散歩です。
今回は、サービス開始から丸12年が経過して複雑になったRuby on Rails製サービスで、安全かつ効率的にデッドコードを消せるようにするために行ったことをお話します。
3行サマリ
- デッドコードを検出するためにcoverband gemを入れようとしたものの、入れたいサービスの規模が大きすぎて入らなかった
- コードの実行状況を集計するシステムを内製して、Redash+GitHubでいつでも見られるようにした
- MCPサーバーでデータをcoding agentにつなぎこむことで、自動的に消せないか模索中
背景
freee最大にして最長の歴史を持つfreee会計は、サービス開始から丸12年経ちました。現時点でRailsの最新バージョンは8ですが、リリース当時はRails3だったようです。長い歴史を感じますね。
それほどの長い時間ユーザーに最速で価値を届けるために機能開発・修正を行っていると、不要になったコードが塵のように少しずつ溜まっていき山となります。山となったデッドコードたちは日々開発に携わるエンジニアたちの認知負荷を上げて注意力を散漫にさせ、既に使われていないので修正しなくていいはずの箇所を修正させて時間を奪い、何かと足を引っ張ってきます。
「なら消せばいいじゃない」と思うのですが、Rubyにおいてはなかなか難易度の高い問題となります。 Rubyは非常にメタプログラミングがしやすい開発言語であるため、あるメソッド名をgrepしても利用箇所を洗い出せるとは限りません。思わぬ場所から呼び出されている可能性があるのです。
やったこと
coverband導入
Rubyの特性上、デッドコードを精度よく検出するためには本番システム上の実行情報を取得・集計するのが一番確実です。
rubyで動的にデッドコードを検出できるライブラリはいくつかありますが、メンテナンス状況・パフォーマンス面等を勘案してcoverband gemを選定しました。
まずはfreee会計に導入する前に、他のサービスでcoverband gemを導入してみました。GitHubレポジトリのREADMEが充実しているので、特に迷う点はありませんでした。
coverbandをfreeeのサービスに導入したときのアーキテクチャ概要は以下の図のとおりです。
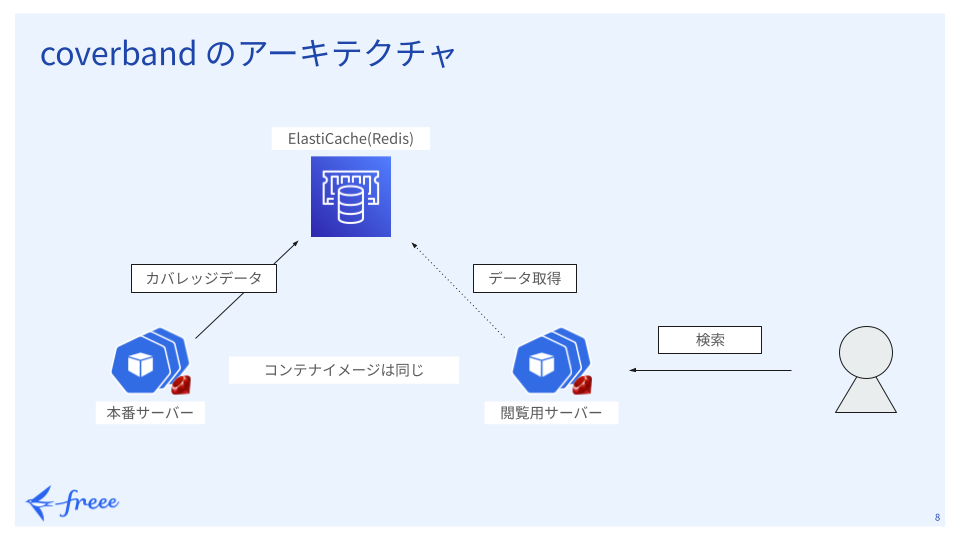
本番サーバーで収集したコードの実行状況を表すカバレッジデータをElasticache(Redis)に格納し、別に立てたcoverbandのデータ閲覧用サーバーにアクセスして結果を確認します。
閲覧画面はこんな感じです。


導入したサービスでは以下の設定を適用し、特に問題なく運用しています。
COVERBAND_HASH_REDIS_STORE=1- デフォルトではredisにデータを保存するときに1つのキーに対して書き込みを行うため、railsのサーバープロセスが大量に並列されていると書き込み時にデータが競合し、正確に集計が行えない可能性が高まります
- この環境変数を設定すると、データの更新処理の一部がRedisに移譲され競合を防ぐことができますが、RedisのCPU負荷は上がります
ONESHOT=1- この環境変数を設定すると、内部的に利用しているRuby標準ライブラリの
coverageをoneshotモードで開始するためアプリケーションへのパフォーマンス影響が最小限になります - ref. Feature #15022: Oneshot coverage - Ruby - Ruby Issue Tracking System
- この環境変数を設定すると、内部的に利用しているRuby標準ライブラリの
余談ですが、そのサービスを開発しているエンジニアにしばらくcoverbandを運用してもらっていたところ、「データ上最後に実行されたのがいつかわからないので、ある程度リファクタリングを進めた後に再集計のためにデータリセットしている。またデータが溜まるのを待つのがじれったい、どうにかならないか(意訳)」という声を聞きました。そこで、最終実行時刻を出す機能を実装してcoverband本体にコントリビュートしたりしました。
freee会計にcoverbandを入れてみたら…
その後も他サービスからの引き合いがあってcoverband導入済サービスが2つになり、勘所が掴めてきたところで本丸のfreee会計への導入に挑戦しました。
しかしfreee会計はcoverband導入済みのサービスと比べて明らかに規模が大きかったため、少しずつ導入を進めている時点で既に負荷が重く一筋縄ではいかないことを悟りました。
何度か負荷対策を入れながらトライしましたが残念ながら結果は失敗に終わり、撤退を余儀なくされました。

撤退した理由としては以下のとおりです。
- ファイル数があまりに多すぎてcoverbandの一覧画面が開かない
- Railsのサーバー台数が多すぎて、データを保存しているRedisがCPU100%に張り付き動かなくなってしまった
- 負荷に耐えられるレベルのRedisを用意しようとすると、リターンに見合わないコストがかかることがわかってしまった
- Railsのwebサーバーは数分に1回だけデータを送信・送信タイミングのランダム化等で負荷を調整できたが、Resqueで非同期jobを利用しているとjobが終わるたびにデータを送信するのでRedisの負荷が膨大になる
coverbandのGitHubレポジトリにもissueやPRを立てて作者の方と話したりしていましたが、この規模でcoverbandを使うユーザーはほとんどいないため需要があまりないようでした。 その上、coverbandの既存のコードを元に修正するには少し複雑になりすぎていると感じたため、coverbandをこれ以上改修することは断念し、内製開発に切り替えることにしました。
内製したデッドコード検出システム
長い背景説明をお読みいただきありがとうございました。ここから本題に入ります。
今回開発したデッドコード検出システムは食べログさんの発表資料 食べログのデッドコード解析基盤の裏側 - TECH Street Ruby勉強会 - Speaker Deck を大変参考にさせていただきました。この場を借りて御礼申し上げます。
システムの概要図は以下のとおりです。
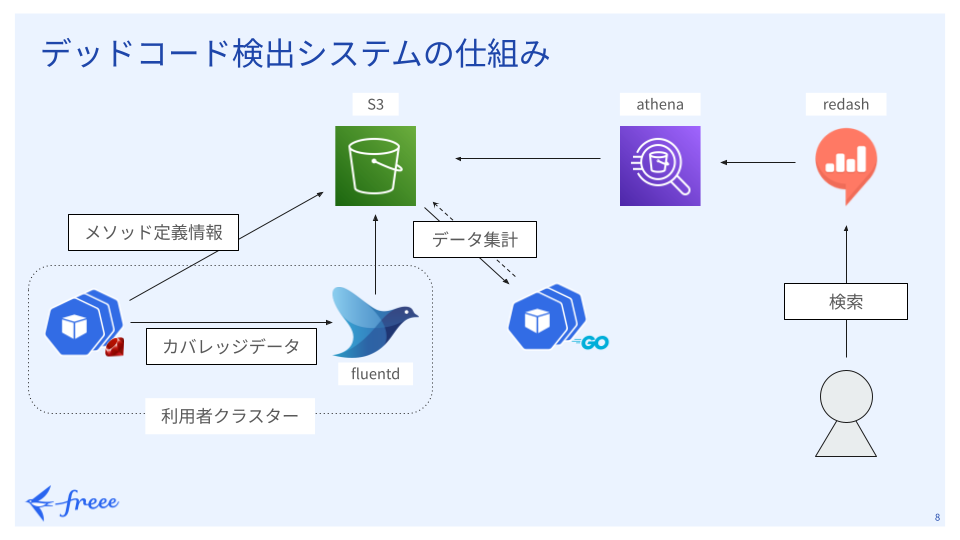
簡単に流れを説明すると、以下のとおりです。
- アプリケーションをデプロイする際にCI/CDワークフロー上でメソッドの定義情報を解析しAWS S3に保存
- 実際に本番アプリケーションが動き始めたら専用gemが動的な実行情報を行単位で保存、数分に1回ログデータ収集ツールのfluentdに送信しAWS S3に配送
- 1日1回データ集計用のGolang製バッチが結果をAWS S3に保存
- 行番号をそのまま集計した行単位カバレッジ
- 行番号とメソッド定義情報を突合したメソッド単位カバレッジ
内部的にはRuby標準ライブラリのcoverageをラップしていて、coverbandや食べログさんの事例と同様にoneshot_linesモードで記録しているためパフォーマンス影響は最小限におさえています。
またデータ集計用バッチはGolangで作ることで、生データのダウンロード・集計等を並列化して高速化を図りやすくしたり、言語系のバージョンアップデートでなるべく手間がかからないようにしています。
デッドコード情報を知りたい利用者は、様々なデータの可視化ツールであるRedashのダッシュボードにアクセスすると集計結果を閲覧することができます。このデータはAWS S3上のデータに対して直接SQLでクエリができるサービスであるAWS Athena経由で取得されています。

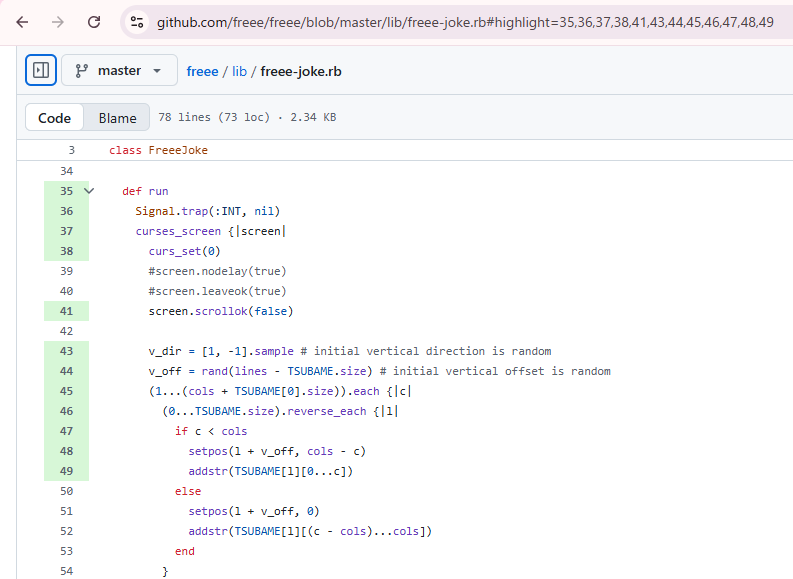
左からクラス名、メソッド名、最終実行日、ファイルパスが並んでいます。
Redashのダッシュボードは結構高機能で、クエリ結果をキャッシュしてくれるためクラス名・メソッド名・パス名等でインクリメンタルサーチができるようになっています。
さらに一番右のpath列はGitHubへのリンクにもなっており、そのリンクを開いて専用のブックマークレットを実行すると行単位カバレッジのデータを元に実行済の行が光るようになっています。
また想定していなかった収穫として、Ruby3.2からevalで評価されたコードのカバレッジも取ることができるようになっていたことがありました。
Feature #19008: Introduce coverage support for `eval`. - Ruby - Ruby Issue Tracking System
ERB等のテンプレートの実行状況も見ることができるようになるため、特に古い画面でありがちな*.rbではないファイルの実行状況を追跡できるのは嬉しいポイントでした。
このデッドコード検出システムは社内での評判もよく、こちらから積極的に導入を勧めるまでもなく導入を検討してくれるサービスが増えた結果、現在ではfreee会計を入れて計4サービスでこのシステムが稼働しています。
MCPサーバーも作ってみた
このシステムを社内で公開して、反応を覗き見するために社内Slackを巡回していたところ「AIがデッドコード消してくれたらな~(意訳)」という嘆きを見かけました。
そこで、クラス名・メソッド名・ファイル名を渡すとデッドコードかどうか判定してくれるMCPサーバーを作ってみたところ、エントリポイントを渡すだけで再帰的に検索をしながら消していいものと悪いものを見分けてくれるような挙動を示しました。しかし、プロンプトを調整しても精度が安定しなかったり、レビュー作業がネックになったりと、削除まで完全自動化することは叶いませんでした。
AIがもう少し進化してくれれば自動でレガシーソフトウェアを綺麗にしてくれる日が来るかもしれません。
まとめ
大規模Railsアプリケーションにおけるデッドコード検出は、既存OSSでは対応しきれないケースがあります。 今回の内製システムでは、fluentd + S3 という構成で負荷を分散し、Athena + Redash経由で開発者が手軽にアクセスできる基盤を構築しました。
山積したデッドコードにお悩みの方は、まずcoverbandを試してみて、規模に応じて内製を検討することをおすすめします。
明日は、シバタさんから「スターの多いOSSは、どのようなAGENTS.mdを記述しているのか調べてみました」という記事が公開されます。お楽しみに。