
freee株式会社の浅羽です。普段はエンジニアリングマネージャーをしつつ、エンジニアの新卒採用も担当しております。昨年度に引き続き、今年度も早稲田大学様での特別講義を行う機会をいただきました。

昨年のレポートについてはこちらをご覧ください。
講義内容を昨年度と比べて何を変えたか
さて、今年度の講義内容を考える上でどこをメインゴールにしようかと考え、最終的に昨年度と同様にアルゴリズムとデータ構造が実際にどう使われているかのイメージをもたせること主軸としました。
- 難しすぎる内容を伝えることで変に挫折感を与えない
- 簡単すぎてもよくないので学びのあるものにしたい
2017年度の講義資料がボリュームや難易度が程よいところだったので、最終的にはだいたい同じ内容で講義することにしました。資料はこちらになります。
- Webサービスの裏側の概要
- リクエストに対してレスポンスを速く返したい
- 何かしらのデータを読み書きすることが多い
- ユーザが識別されることが多い(ログイン機能等)
- RDBMSで使われているアルゴリズムのうちの一部
- B+Tree
- ソート (クイックソート、マージソート、Top-K selection)
- テーブル結合(Nested Loop Join, Merge Join, Hash Join)
- いかに速くデータを検索・操作するかの一例として紹介
- KVS
- セッション管理を例に紹介
- ユーザの識別の一つの手法として紹介
- キュー
- 非同期処理を実現するためのコンポーネントとして紹介
- レスポンスタイムを早くするために急いで処理しなくても良いものは後回しにするよ、という説明
練習問題
こちらも昨年と同様にテーブル結合を3つのアルゴリズムを実装してもらい、入力データが大きくなった場合にどれくらい実行時間が変わってくるかを計測してもらいました。
Nested Loop Joinに関しては内部表のスキャンはフルスキャンのみ実装している前提なので、実際はB+Treeからのフェッチでそこまで重くならないこともあるよ、とは口頭で補足しつつ、データが数十万件くらいになると大きく実行時間が変わってくるのを体験してもらいました。
GitHubに解答例を置いておきました。
結果どうだったか?
講義が終わってから匿名でアンケートを取り、42名の学生の方から回答をいただきました。ご回答ありがとうございます!
本日の講義を、知人や友人に勧めたいと思われますか?
- 「ぜひ勧めたい」を10、「全く勧めたくない」を1とした場合の10段階評価でご登録ください。
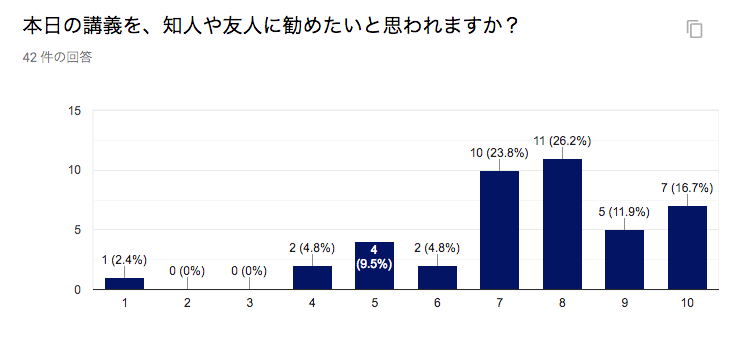
NPS(ネットプロモータースコア)という、顧客(今回の場合は学生さん)の推奨度の測定で用いられる手法で計算をすると、 (12 - 9) / 42 * 100 = 7.14となりました。この数字の絶対値の適正がどこかはわかりませんが、昨年も同様のアンケートを取ったところだいたい同じくらいの数字でした(経年で追いかけるのが大事だなと思いますので、次回も同じ方法でスコアを計算して改善したかどうかを計測したいと思っています)。
一方で1を一人でもつけさせてしまったのは、私の講義の改善の余地が十分にありそうなので、定性コメントにある内容をまずは改善していこうと思います。
本日の講義の難易度はいかがでしたか?
- 「難しすぎた」を5、「簡単すぎた」を1、「丁度よかった」を3とした場合の5段階評価でご登録ください。

定性コメントの抜粋(私が一部コメントを編集)
以下のように良い点と改善点のフィードバックをいただきました。特に資料については字を詰め過ぎたりしている箇所があるので、次回また講義する機会がある際には修正しようと思っています。
- 回答
- 実際にどう使われるのかイメージができた
- 演習問題が適切でよかった
- 後ろの方からだと資料の字が小さかった
- 演習問題の回答がほしい
まとめ
今回は2回目の講義になりましたが、内容や難易度に関しては程よいサイズだったのかなと思います。一方で改善のポイントは大いにありそうなので、プレゼン能力等を改善しつつ、学生の方にとって学びのある講義を引き続き提供できればと思っております。
宣伝
freeeでは現在2020年新卒エンジニアを積極採用中です。もし興味ある方はfreeeの新卒採用ページをぜひ御覧ください!