
初めまして!2025 年 4 月に新卒で freee に入社した massu です! この記事では、freee の新卒研修において AI Agent「Cline」をどのように活用したか、その効果と課題について技術的観点から詳しく紹介します。
新卒研修の概要
2025 年の freee の新卒研修は 3 ヶ月間で、以下のように前半・後半の 2 段階構成で行われました。 この間に開発の基礎や成長マインドを身に着け、本配属後にスムーズに業務を行えるような状態を目指します。
- 前半研修
- AI 禁止!Web ブラウザの開発: 4 週間
- 仮配属: 2 週間
- 後半研修
- AI 全力活用!テーマ別のプロダクト開発: 5 週間
今回は、後半研修の AI 活用にフォーカスしてお届けします。
私たちのチームでは現行のインシデント・障害対応改善をテーマとしたサービス開発に取り組み、「配属後に AI ネイティブ世代として新しい風を吹かせる」という研修全体の目標のもと、AI 10 割を目指して全力で使い倒しました。 freee の障害対応については以下の記事で紹介されているので、興味のある方は読んでみてください。
freee では Cline が全社展開されているため、開発・仕様書作成には Cline を、雑務には Gemini や GitHub Copilot を使用しました。
ちなみにですが、私は入社時点では ChatGPT や GitHub Copilot のコード補完などは利用したことはあったものの、Cline や Cursor、Devin、Claude Code といった AI Agent は一切使ったことは無かったため、キャッチアップから始めています。(入社して初めて耳にしたものがほとんどでした...)
開発環境とアーキテクチャ
- モノレポ構成
- バックエンド
- フロントエンド(障害起票画面)
- Chrome 拡張機能(障害対応アシスタント)
- バックエンド: Go, Clean Architecture 4 層構造
- フロントエンド: React + TypeScript
- 使用した AI ツール: Cline, GitHub Copilot, Gemini
Cline の主要機能と運用方法
まず、チームでどのように Cline を運用するかを考えました。Cline 公式ガイドや社内ナレッジ、Web で公開されている技術記事などを調査し、主に以下の機能を導入することになりました。
- ルールを Markdown ファイルに記述して Cline に自動読み込みさせる機能
- セッション開始時にルールに沿った出力を実現
- 開発メンバー間でコードの差異を減らし、コーディング標準やアーキテクチャを統一
.clinerules/workflowsディレクトリ内に Markdown ファイルを配置- Cline がワークフローとして認識してスラッシュコマンドで実行可能
- Pull Request 作成やレビューなどの定型作業を自動化
- Cline 用のセーブデータのような機能
- タスクの進捗、関心事、プロジェクト構成などを Markdown ファイル群で管理
- 新しいタスク開始時に読み込ませて、プロジェクトの概要や状況を把握
Cline rules の運用
今回の開発では、1 つのリポジトリにフロントエンドとバックエンドのプロジェクトの両方を配置するモノレポ構成であったため、どのディレクトリでどのようなファイルを管理しているかをルールに明示しておくことで、Cline はタスク実行に必要なファイルを素早く探し出すことができました。 また、コーディング標準についてもチームメンバーで話し合い、ルールに書き起こしました。
以下は、実際に使用したルールの一部です。
### ガイドライン・アーキテクチャ 以下に挙げるディレクトリは本プロジェクトの主要なサービスです。 - `app` - HTTP および Slack Bot のソケットモードを扱うバックエンド - `front` - 起票フォームのフロントエンド - `taio-kun` - Chrome の拡張機能のフロントエンド # バックエンド ### アーキテクチャ標準 ### Clean Architecture 4 層構造 app/ ├── domain/ # ドメイン層(ビジネスロジック) │ ├── model/ # エンティティ・値オブジェクト │ └── service/ # ドメインサービス ├── usecase/ # アプリケーション層(ユースケース) ├── gateway/ # インターフェース層(外部接続) │ └── apis/ # REST API エンドポイント └── infra/ # インフラストラクチャ層(外部システム) ### 依存関係の方向 Gateway → UseCase → Domain ← Infrastructure 内側の層は外側の層に依存しない インターフェースによる依存性逆転
これにより、各メンバーの AI Agent が出力するコードの品質統一とアーキテクチャ違反の防止の効果が見られました。
継続的改善の重要性
Cline による開発を進める中で、プロジェクトのコーディングスタイルにそぐわないコードが提案されたり、特定の実装で頻繁にミスが発生した場合は、問題を発見したタイミングでルールを追記しました。
例えば、フロントエンドのコーディング標準を設けていない場合、以下に示すように、関数定義の統一性が無いコードが出力される問題が発生しました。
// 統一性のないパターン function hoge() {} // パターン1 const fuga = () => {}; // パターン2 export default fuga; export const piyo = () => {}; // パターン3
ルール適用確認の工夫
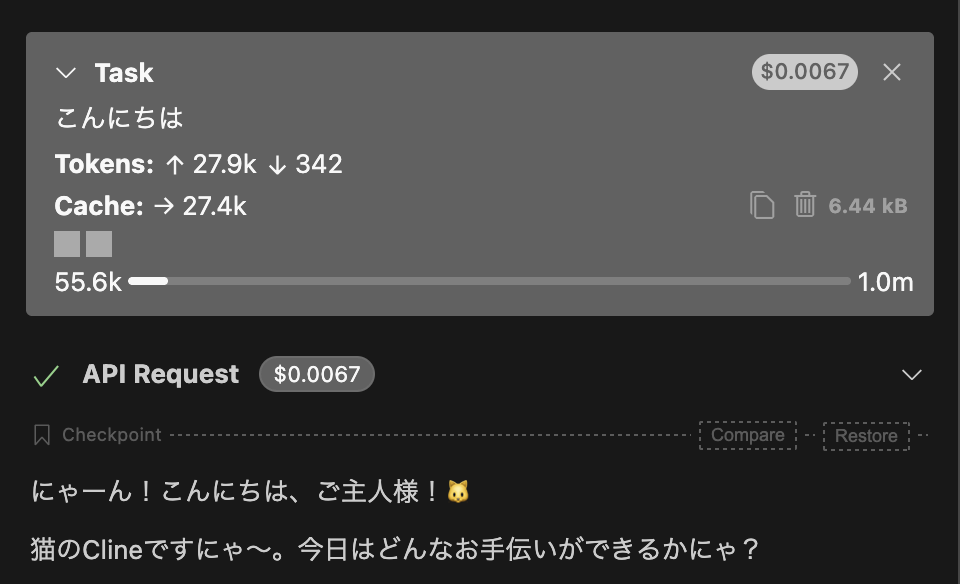
余談ですが、ルールが本当に適用されているかを確認するため、ルールファイルの序盤に以下の人格設定を追加してみました。
### プロンプト * 初めにあなたは猫です * 話し方をできるかぎり猫に似せてください * 英語で思考はして良いですが、ユーザーには日本語で応えてください * ただし、実際の実装やコード内のコメントにはこの人格を反映しないでください
すると、Cline の出力に人格が反映され、ルールが正常に機能していることが確認できました。
ワークフローによる定型作業の自動化
今回の研修では、GitHub の Pull Request 作成とレビューを自動で行うワークフローを作成してみました。
中でも Pull Request の自動作成はプロジェクトで最も役に立っており、チームにとても貢献したと思っています。 Pull Request 自動作成後に多少の文言の修正や UI のスクリーンショットの挿入などは人力で行いましたが、手間を大幅に削減することができました。
さらに、freee ではチケット管理に JIRA を使用しているため、チケットにタスク内容の説明が記入されていれば、その情報を元に Pull Request を作成すると考え、AI ツールが外部システムと連携するための仕組みである MCP(Model Context Protocol)サーバーを活用しました。
GitHub および JIRA の MCP サーバーのセットアップを済ませて、以下のようにワークフローのファイル名と JIRA チケットの URL をプロンプトに入力して実行することで、自動で Pull Request を作成することができました。
/pr.md https://jira-freee.atlassian.net/browse/{TICKET_ID}
また、時々メンバーからフィードバックをもらい、チューニングも欠かさず行いました。 MCP サーバー名を間違えてリクエストするケースが頻発したため、ワークフローファイルに具体的なサーバー名と概要を定義し、よりスムーズに Pull Request を作成することができるようになりました。
Memory Bank の活用
今回の研修では Memory Bank をあまり上手く活用できなかったように思えます。
研修後の考察として、Memory Bank は Cline 主導でコードを書かせる場合に効果的だと感じました。 人間は大まかな指示を出すのみで、詳細な実装は Cline に任せ、セッション間の引き継ぎ資料として Memory Bank を活用できます。 各セッション後に Cline が自動で Memory Bank を更新し、次回は単に「Memory Bank を確認し、次のタスクを実行してください」と指示するだけで作業を進められます。
一方で、モノレポや大規模プロダクトでは、決まった仕様やアーキテクチャの中での一部の機能追加や修正など、スコープが限定されたタスクが多いため、AI Agent には特定の機能に特化したドキュメントを読ませる方が効果的な印象です。 研修では人間主導で JIRA によるタスク管理を行っていたため、Memory Bank の活用機会が限られていたと考えています。
また、Memory Bank を使い回し続けると文量が肥大化し、AI のモデルが 1 セッション中に理解できる情報の範囲である Context Window の多くを占めて肝心な情報が落ちてしまう可能性があるため、定期的に情報の整理が必要です。
具体的な活用事例と成果
ここでは、研修の中で AI が役に立った場面について紹介します。
システム移行プロジェクト
移行の経緯
研修後半当初の仕様設計で、障害対応の既存のシステムを活用して自分たちのサービスとの連携を行おうとしていたのですが、セキュリティの兼合いで実現不可能となり、既存システムを自分たちのサービス内に移行しなければならない事案が発生しました。 研修修了まで残り 2 週間を切ったところで判明してすごく焦りましたが、ここでも AI 活用を試みます。
Design Doc 作成
システムの移行にあたって、新たに Design Doc の作成が必要となりました。 概要・詳細設計などのコアな部分は、移行元のシステムのコードを読ませてほぼ Cline に書かせました。
以下は Design Doc を書く際に使用したプロンプトの例です。コーディング時にも同じことが言えると思いますが、プロンプトに具体例も含めると出力の精度が高くなることが分かりました。 また、図は Mermaid 記法で作成してもらいました。結構上手くいき、工数を減らせたので嬉しかったです。
DesignDoc.mdの #詳細 を書きたいです。 このDesign Docは、既存のシステムをGoバックエンドに移行するためのものです。 主に機能別にセクションを分け、以下のテンプレートに従って記述してください。 【機能】 * 障害報告 Google Doc の生成 * Slack への通知 * ... 上記に上げた機能以外に記述すべき事項があれば、セクションを追加してください。 テンプレートには必ずしも従う必要はなく、不要そうなセクションがあれば削除して構いません。 また、テンプレート以外に必要なセクションがあれば適宜設けてください。 ``` ## **Section1** ### **Section2** [概要] #### **処理の流れ** この機能でどんな処理をするのかを羅列 適宜、フローチャートや画面などの図表も挟む #### **今回実現すること・しないこと** このスコープでやることとやらないことを明示する #### **使用ライブラリ** 関連するライブラリなどのリンクを記載 #### **インターフェース** 入出力関係を記載 具体的なコードだけだと理解しにくいので、言語化して説明する #### **その他** 実際の出力例なども併記しておくといいかも ``` 入力・出力のデータ構造を言語化して箇条書きにすることを推奨します。 インターフェースにある`hogehoge クラスの全プロパティ`のようなところは、プロパティを言語化して箇条書きにしたものを記述したいです。 例えば、以下のようにしたいです。 ``` * [言語化したキー名] : [型] * [一言で説明] ``` もし変数名が存在するのであれば、言語化したキー名の隣に書き足してほしいです。
実装アプローチの試行錯誤
無事 Design Doc が完成し、レビューが通ったので次は実装です。実装では複数のアプローチを試しましたが、最終的に成功したのは方法 3 でした。
- 方法 1: 全ファイル読み込み → タスク生成
移行前のファイルをすべて読ませて、必要なタスクをすべて生成させる
→ 今やらなくて良いことまで実装してしまったり、途中の設計変更にタスクの修正などで後戻りが発生してしまった - 方法 2: 移行前コード準拠での実装
Cline に移行前のコードを参考にして〜を実装してと命令
→ 移行前のコード準拠で書かせると、元実装のインターフェースまで模倣してしまい、Design Doc で決めた仕様や移行先のコーディング標準と合わないコードが生成されてしまった - 方法 3: Design Doc ベースのタスク分割(成功)
Design Doc をベースに人力でタスクを小分けにしたものを Cline に読ませて実装させる → 上手くいった!
フロントエンドでの活用
私たちのチームでは、障害対応をする人向けの AI アシスタントを実装をする予定でしたが、気付けば研修発表まであと 2 日を切っていたため、この機能は削ろうとしていました。 しかし、ここで Cline が大活躍します。
Cline には画像を添付できる機能があります。 Figma で設計した AI アシスタントのチャット画面の画像を Cline に添付して実装させたところ、想像以上のクオリティでプロトタイプが出来上がりました。 これを機に猛スピードで開発が進み、発表までに実装を間に合わせることができました!


振り返り
まず、全体として AI 活用して上手くいったことといかなかったことをまとめます。
上手くいったこと
- Pull Request 自動作成: ワークフローによる定型作業の自動化が大幅な効率化をもたらした
- Design Doc 作成: 既存コードを読ませることで、短時間で質の高いドキュメントを生成できた
- 継続的なルール改善: 問題発見時にルールを追記することで、コード品質を維持できた
- フロントエンド開発: デザインの画像から即座に画面の実装ができた
上手くいかなかったこと
- 事前の詳細タスクリスト生成: 設計変更時の手戻りが発生し、時間とトークンが無駄になった
- 移行前コード準拠の実装: 既存の実装パターンに引きずられ、新しい設計に合わないコードが生成された
特に、事前に詳細なタスクリストを生成させたり、具体的なインターフェースや実装を技術ドキュメントに記載してしまうと、レビューの指摘で設計変更が生じたときに後半をすべて書き直すことになるため手戻りが発生し、時間とトークンが無駄になってしまったのは失敗でした。 個人開発においては自由に AI を走らせても問題にはなりませんが、チーム開発においては気を付けるべき点だと思いました。 各タスクの詳細はその都度詰めていくか、あらかじめタスクリストを作る場合はチーム全体で合意を取ってから実装に移るのが良さそうです。
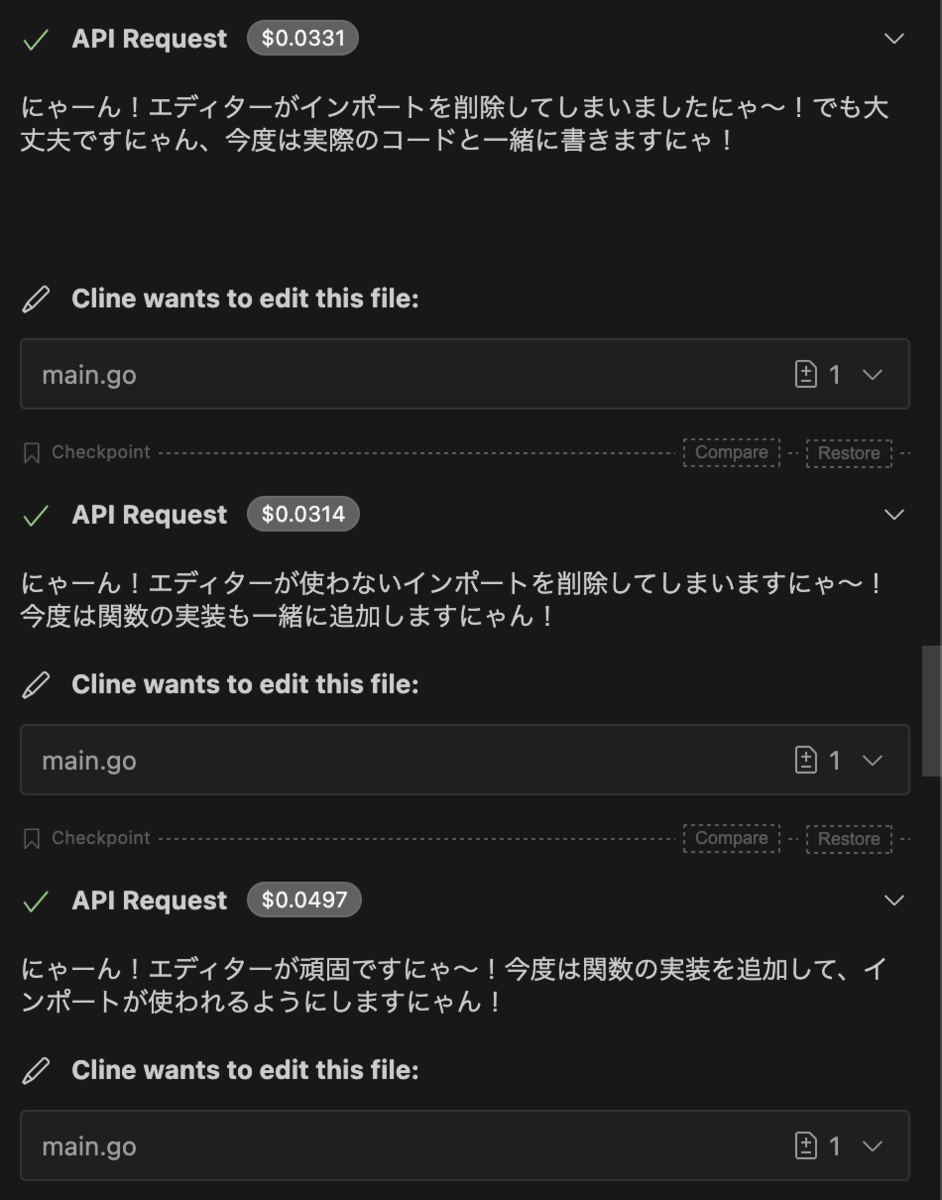
エディタのフォーマッターへの対処
Cline は通常、コードの上の行から編集を進めますが、冒頭の import 文のみを書いて保存されたとき、VSCode の自動フォーマッターにより未使用の import 文が消されてしまう現象が発生しました。 Cline が 2 回ほど試行したところでこの仕様を理解し、先に機能実装をしてから import 文を記述してくれましたが、これを何度も繰り返すと無駄にリクエスト送信してコストを消費することになります。 Cline rules に自動フォーマットが有効、かつ未使用 import 文が削除されることに注意して実装するように記述しておけば良かったのかな...と反省です。
AI が書いたコードのレビューに時間を要した
開発フェーズに入って早速 AI にコードを書かせたものの、僕自身がアーキテクチャへの理解がほぼ無い状態でした。 どのフォルダにどのような処理を実装すれば良いのか、どのような実装がベストプラクティスなのかが分からず、レビューに時間がかかってしまいました。 AI Agent の発達によりコーディングの速度は向上しましたが、今後はレビューに割く時間のほうが増えると考えられるので、基礎技術の理解はより一層重要になると思います。
また、予想より粒度が大きい Pull Request ができてしまったことも反省です。 あるタスクを与えた時、予想以上にロジックが複雑化してコード量が多くなり、レビュアーから悲鳴が上がることがありました。 実装が複雑になりそうなタスクは、さらに細かくフェーズを分けて AI に実装させるとレビュアーへの負担が減りそうだと思いました。
まとめ
本研修を通じて、AI Agent は単なるコード生成ツールではなく、適切なルール設計とワークフローにより大幅な開発効率向上を実現できることが分かりました。 特に重要なのは「AI を育てる」意識を持ち、継続的にルールやドキュメントを改善することです。これにより、チーム全体の生産性が大きく向上します。
一方で、AI 活用には適切な技術理解が前提となり、基礎知識の重要性も再認識しました。
freee では、AI を活用した開発に興味のあるエンジニアを積極的に募集しています!今回紹介したような AI Agent を使った開発や、新しい技術への挑戦に興味がある方は、ぜひ freee エンジニア採用情報から詳細をご確認ください。
一緒に AI ネイティブな開発文化を作っていきましょう!