
読まなくても良い漫才パート
ボケ「いきなりですけどね、freee人事労務の給与計算ロジックでいつも使ってる DB instance があるらしいんやけど」
ツッコミ「あっ、そーなんや」
ボケ「うちのオカンがね、reader instance なのか writer instance なのかをちょっと忘れたらしくてね」
ツッコミ「どうなってんねそれ」
ボケ「でまあ色々聞くんやけどな、全然分からへんねんな」
ツッコミ「分からへんの?いや、ほな俺がね、どっちの instance なのか、ちょっと一緒に考えてあげるから。詳しく教えてみてよ」
ボケ「オカンが言うには、どちらかというと CPU 利用率がいつも低い方らしいねん」
ツッコミ「おー reader instance やないかい。freee人事労務 の DB で CPU 利用率が低い方は reader instance や。黄色の折れ線の方や。reader instance に向いてるクエリの方が少ないねん」
ボケ「いや俺も reader instance と思うてんけどな」
ツッコミ「いやそうやろ?」
ボケ「オカンが言うには、この Job は給与計算をして、最後に計算結果を DB に書き込むらしいねんな」
ツッコミ「あー ほな reader instance と違うかぁ。 reader instance には書き込みできないもんね。」
ボケ「そやねん」
ツッコミ「ほな writer instance や」
ボケ「でも分かれへんねん」
ツッコミ「分からへんことない。使っとるのは writer instance や、もう」
ボケ「でも Job のロジックは、DatabaseSelector.connected_to_reader に渡す block の中で実行されらしいねん」
DatabaseSelector.connected_to_reader do ActiveRecord::Base.transaction { kyuyo_keisan_logic() } end
ツッコミ「ほな writer instance ちゃうやないかい。DatabaseSelector はfreee人事労務の中にある writer と reader の切り替えを行うための class や。その class の connected_to_reader と言うメソッドを呼んでるんやから reader instance やがな」
ボケ「そやねん」
ツッコミ「先ゆえよ。俺が writer instance の話してる時どう思っててんお前」
ボケ「申し訳ないよだから」
ツッコミ「ホンマに分からへんがなこれ。どうなってんねんもう」
ボケ「んでオトンが言うにはな」
ツッコミ「オトン?」
ボケ「Local Write Forwarding ちゃうか?って言うねん」
ここから本題
freee人事労務の人事給与領域のエンジニアをしています、まっつーです。 先日freee人事労務の給与計算ロジックに Local Write Forwarding を利用する施策を本番リリースしたのでその話をします。
Local Write Forwardingとは
Local Write Forwarding (以下LWF)とは reader に向けて貼った transaction の中で、 write の query だけを writer instance に転送してくれる仕組み。
凄い。
Aurora の3.04から使えます。
なぜ使おうと思ったか
前々からfreee人事労務の DB は writer の CPU 負荷が問題になっていました。
主には給与計算を行う Job が一度に多数実行されることにより writer instance へ大量の query が発行されることが原因で、担当チームとしては alert が鳴るたびに給与計算 Job の enqueue 数を見ては「あー、いっぱい積まれてるなー。申し訳ねえなー。」となっていました。
freee人事労務の DB は reader instance と writer instance が用意されていますが、給与計算はドメインロジックの性質上トランザクションの中で給与計算に必要な情報の取得をし、計算した後計算結果を保存するという処理を行なっているため、すべてのクエリを writer に向けるしかありませんでした。
課題感はあるが、これという打ち手がなく困っていたところ、社内の DBRE チームの方から LWF という仕組みを使って負荷が軽減できるかもという提案が。
reader に向けてトランザクションを発行し、write query だけ writer に送るという夢のような仕組みがあるらしい。
まじか、凄い。
早速導入の検討を始めました。
導入の進め方
1. DBRE チームと相談し進め方を決定
freee人事労務チームと DBRE チームで、実際に LWF を導入するにあたっての懸念事項を話し合いました。
話したメリット、デメリット、デメリットに対しての見解は以下の通りです。
導入のメリット
reader を有効活用することにより、writer の CPU 負荷軽減ができる
以下で詳しく述べるが、最終的にはユーザーの「すべての給与計算が終わるまでの待ち時間」を減らせる可能性がある
導入のデメリット
使えない SQL がある
LWF 特有の bug がある
給与計算 Job の Latency が落ちる
将来 Aurora Limitless を使うのであれば徒労に終わる可能性がある
デメリットに対しての見解
使えない SQL がある
LWF を有効にする場合以下の SQL は利用できないようです。
- SAVEPOINT ステートメント
- DDL
- XA
- LOAD DATA
- 一時テーブルを使って書き込みをしようとする物
これら全て、今回導入の対象とする給与計算 Job では使っていないので問題なしとしました。
LWF 特有の bug がある
DBRE チームのメンバーが見つけて AWS に教えてあげたらしいです。 すごいぞ freee の DBRE チーム。
まだ枯れていない技術のため同様に Bug が隠れている可能性はありました。 結果不整合による給与計算結果の差分が発生することは怖いので、検証の期間を設けることにしました。
Latency が落ちる
LWF は reader instance に対して transaction を貼りつつ、write query を writer に転送する技術なので、転送分だけ遅くなります。 freee人事労務では、ユーザーが従業員一人一人の給与をそれぞれ計算するよりは、全社員や同じ支払日の従業員という単位で複数従業員の給与をまとめて計算することが多いです。 そして全ての給与計算が完了するまでユーザーは給与の確定をすることができないため、待ち時間となります。
給与計算 Job は基本的に複数台の replica で並列実行されるため、Job の一つ一つが速く終わることよりも、ユーザーが一度に実行した Job 全てが速く終わることに意味がある機能だと考えています。 なので、一つ一つの Job の Latency が落ちても DB にかかる負荷が大きく軽減できれば、給与計算 Job を実行する worker の数を増やすことができる。 最終的に複数の給与計算が速く完了できるようになりユーザー体験をより良くできると判断して、 Latency の悪化を受け入れることにしました。
将来 Aurora Limitless を使うのであれば徒労に終わる可能性がある
https://aws.amazon.com/jp/blogs/news/join-the-preview-amazon-aurora-limitless-database/
これまた夢のような仕組みらしいですが、まだ MySQL がサポートされてないしどうせ高いのでそこまで考えなくて良いだろうとなりました。
また、上記4点以外にもまだ世の中的にあまり使われていない技術を、いきなり給与計算というfreee人事労務のコア機能であり、計算結果が正しいことが重要視される機能に導入することについても懸念が上がりました。
それに対しては
- 給与計算結果の diff check を行うことで安全に検証を進めることができること
- 給与計算 Job よりは問題発生時にクリティカルな影響にはならず、かつ一つの transaction の中で read と write を行う機能がなかったこと
から給与計算 Job に対して LWF を使う方針を進めることにしました。
2. LWF を利用するできるように各環境で準備を行う
各環境の RDS への対応は DBRE チームで行なってくれました。
また、人事労務の内部品質チームが application コード上で DB instance を選択する際に利用する DatabaseSelector.connected_to_reader というメソッドが enable_write_forwarding 引数を取れるようにしてくれました。
LWF では読み取り整合性のレベルを
- EVENTUAL
- SESSION
- GLOBAL
から指定することができます。
事前に DBRE チームと SESSION レベルで指定することを合意していたので、enable_write_forwarding: true とした時には SESSION レベルで LWF が有効となる実装をしてもらいました。
3. LWF を利用した場合としない場合で、結果に差が生まれないことの確認
freee人事労務 では既存機能を新ロジックに置き換える時によく使う方法ですが、旧ロジックと新ロジックを本番環境で両方実行しつつ、差分があったときだけクラッシュレポートに warning レベルで通知するという方法で安全であることを確認しました。
また、いきなり本番適用は怖いのでfeature flag を使い、本番で実行される給与計算の5%に対して diff check を実行しました。
具体的には給与計算 Job が diff check 対象の場合
LWF を利用した状態で給与計算を実行、計算結果を変数に代入
Rollback し給与計算結果を破棄
LWF を利用しない状態で給与計算を実行、計算結果を変数に代入
Commit し給与計算結果を保存
変数に代入していた各給与明細項目の金額を比較
差分があればクラッシュレポートへ通知
という処理を行い、LWF を利用したことに起因する結果不整合が発生しないかを検証しました。
以下のような実装のイメージです。
def execute(employee_id) diff_check_percentage = [[FeatureFlag.value('lwf_diff_check_percentage'), 100].min, 0].max enable_diff_check = diff_check_percentage != 0 && employee_id % (100 / diff_check_percentage) == 0 before = [] after = [] if enable_diff_chedck # LWF を有効にして給与計算を実行、変数に計算結果を保存した後 Rollback DatabaseSelector.connected_to_reader(enable_write_forwarding: true) do ActiveRecord::Base.transaction do employee = Employee.find(employee_id) kyuyo_keisan_logic(employee) before << KyuyoKeisanKekka.find_by_employee(employee) raise ActiveRecord::Rollback end end end # LWF を無効にして給与計算を実行、変数に計算結果を保存した後 Commit DatabaseSelector.connected_to_reader(enable_write_forwarding: false) do ActiveRecord::Base.transaction do employee = Employee.find(employee_id) kyuyo_keisan_logic(employee) after << KyuyoKeisanKekka.find_by_employee(employee) end end if before != after CrashReportNotifier.notify('LWFを利用した給与計算結果に差分があります。') end end
検証を始めてdiff が出たかでいうと、結構出ました。
理由としては、freee人事労務はユーザーが打刻をする、人事情報を書き換える、など給与金額に変更が起こり得る操作が数多くあります。
なので上記の処理のうち LWF を有効にした給与計算実行開始から、LWF を無効にした給与計算の実行開始までの間にそれらの操作を実行されると給与計算に用いるデータが異なるので結果が異なります。
給与計算は1回が大体3-4秒程度で、その間に給与計算に用いるデータを変更する操作が行われる可能性はかなり高いです。
ある程度自動的に省けるものは通知対象から省きつつ、残りはクラッシュレポートの情報から実際のユーザー操作を確認し、納得感のある diff しか通知されていないことを確認し、安全性が検証できたと判断しました。
また、Stagingでの動作確認中に LWF に利用する writer への接続数の上限にあたりエラーになるという事象が発生しました。
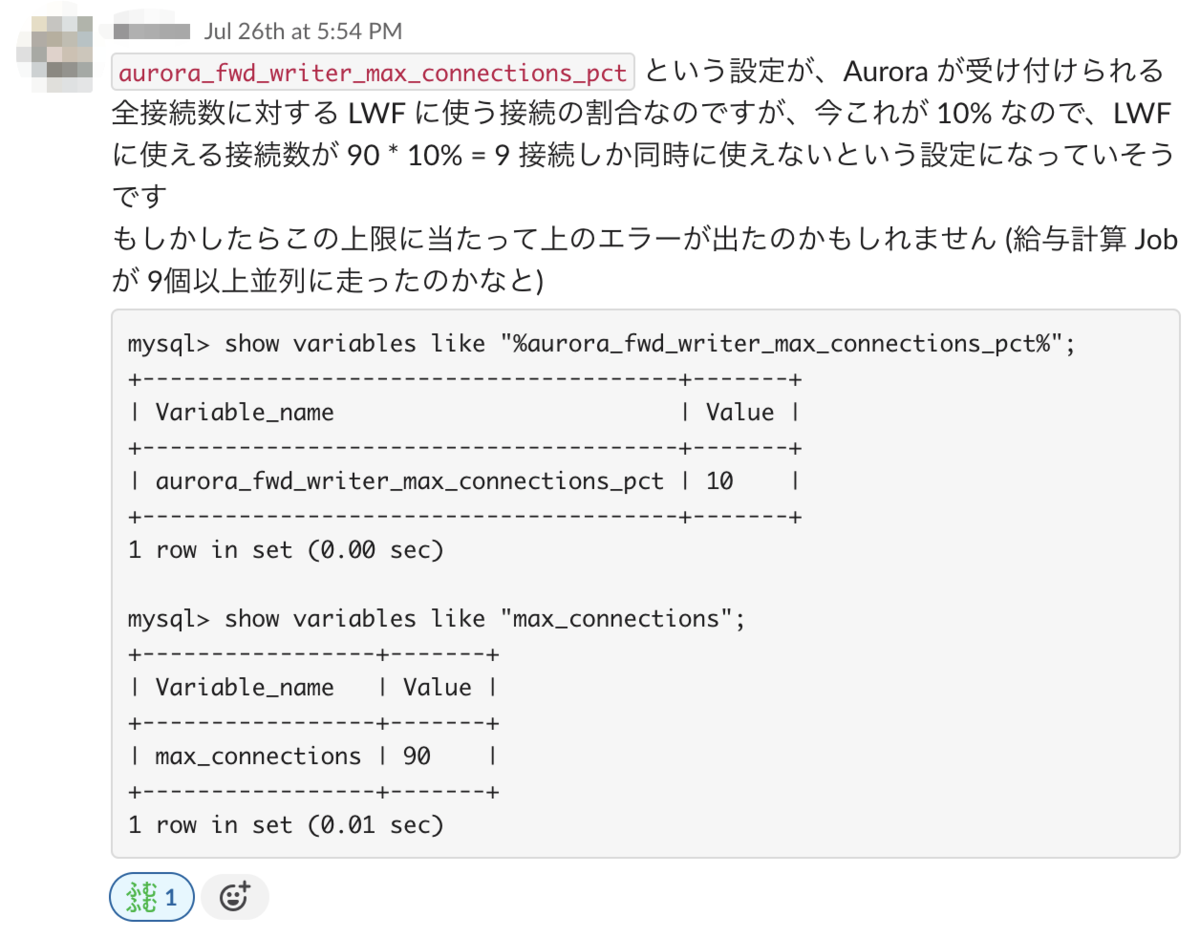
本番環境での設定値と最大の writer への connection 数を確認し、本番では同様のエラーが発生する恐れがないことを確認しました
4. 段階的なリリース
本番での diff check で安心感を得ることができたので、次は diff check ではなく実際に LWF で給与計算を行うコードに変更し、本番に反映しました。
本番反映の際も何かあった時にすぐ対応できるようにまずは全体の 5% の給与計算に対して適用、その後 50% まで引き上げました。
LWF 50% 適用の時点でかなり効果を実感することができました。
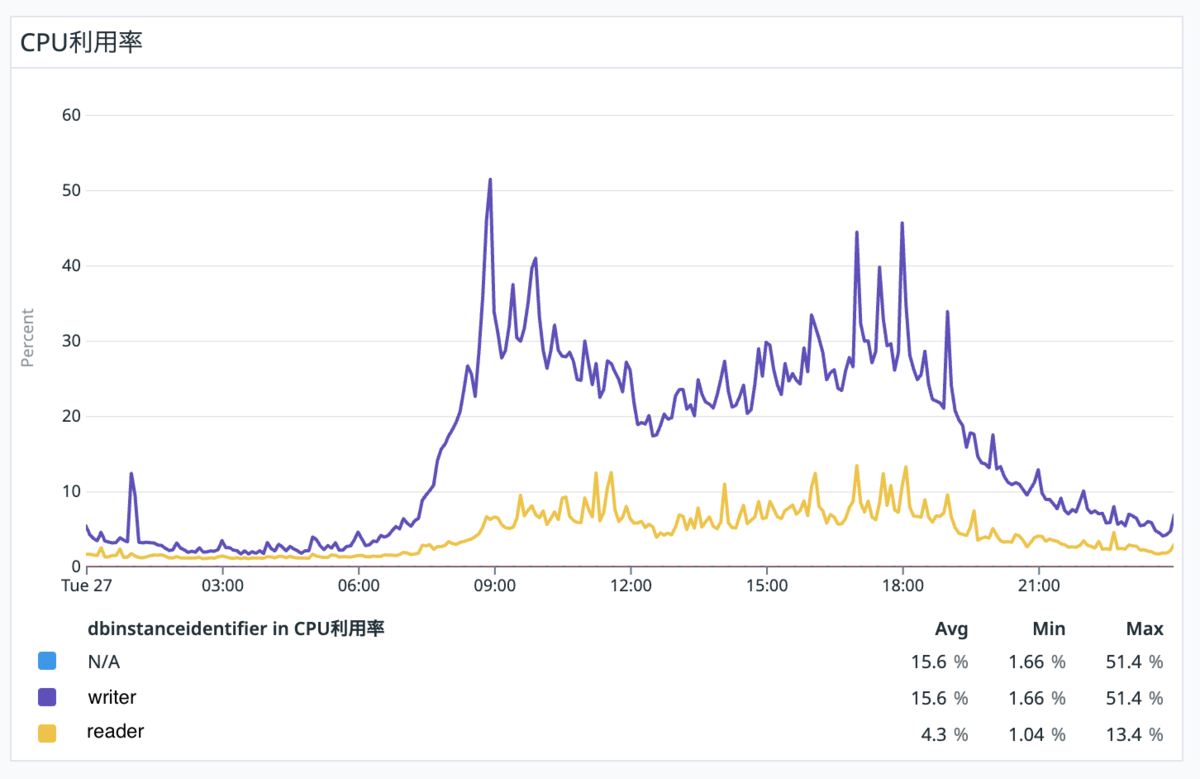
今ままであれば DB の CPU 利用率 alert がなっていたような 6000 件の給与計算が実行された際に、reader の CPU 利用率が 5% => 35% に上昇しており、一方 writer の利用率は 20% => 40% の上昇に抑えたまま捌き切れています。
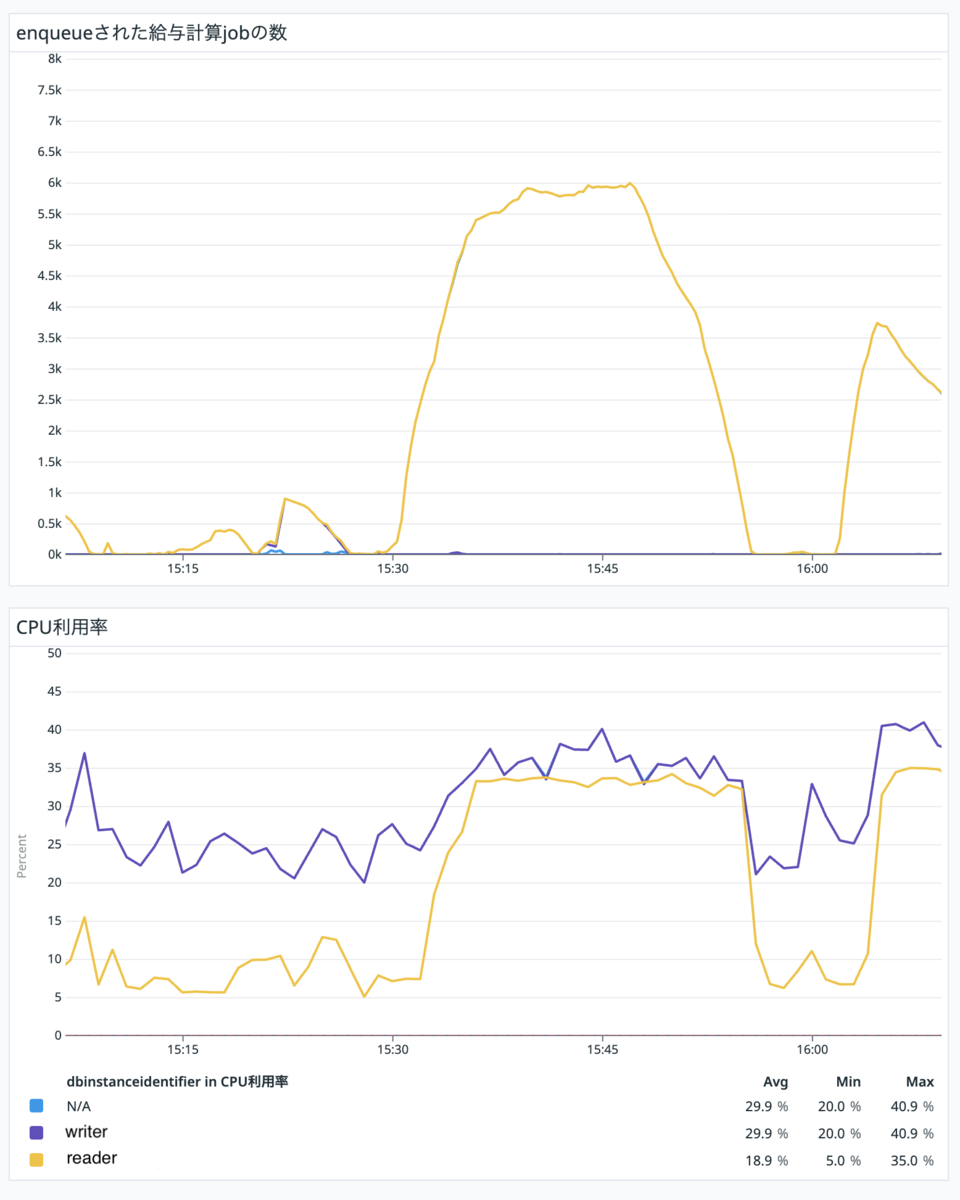
すごいぞLWF!
その後はこのままいくとピーク時にreaderの負荷の方がwriterの負荷を超えることが予想されるので50% => 75%を挟み、9/4についに100%LWF利用になりました。
100%になると予想通りreader instanceのCPU利用率がwriter instanceのCPU利用率を超えるタイミングが確認できます。
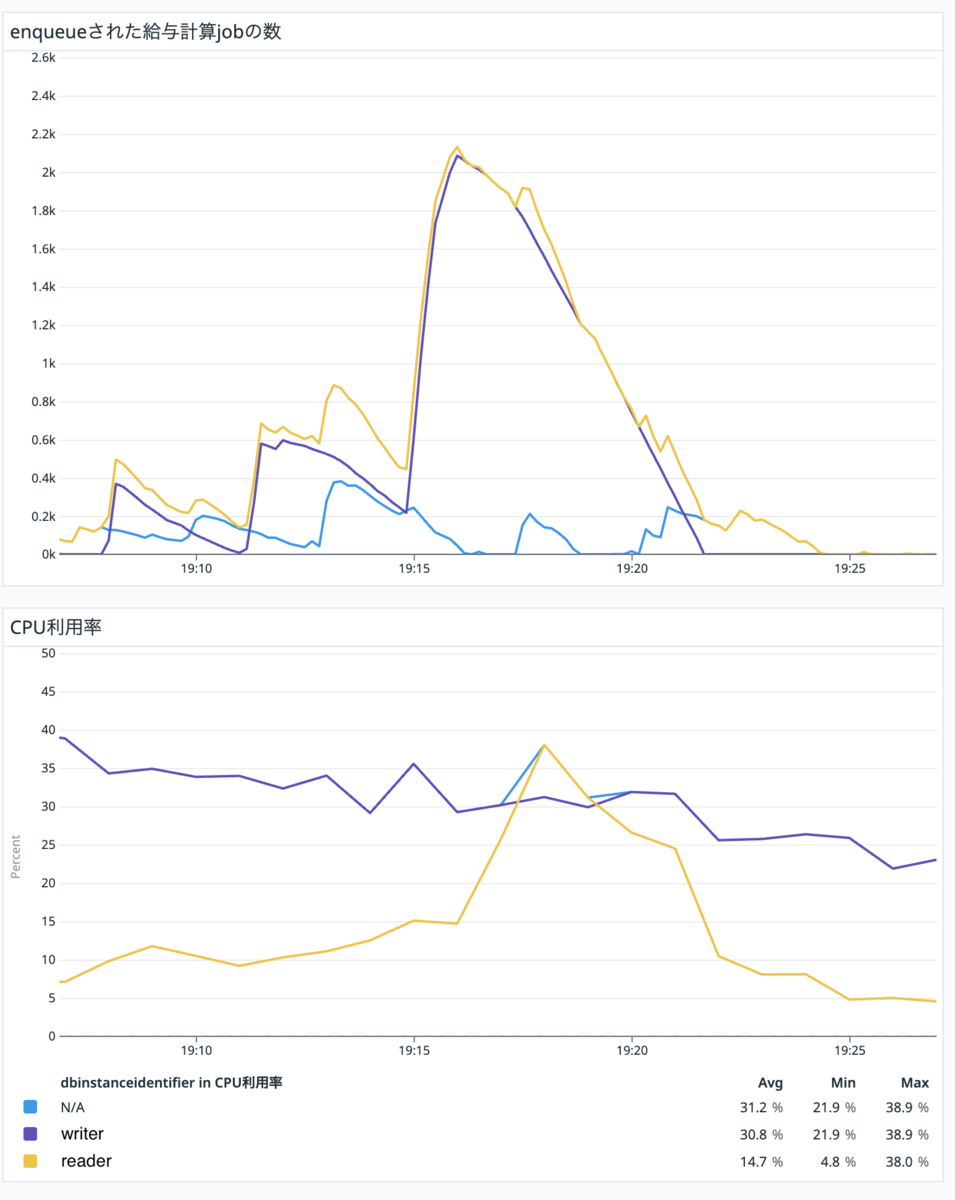
こうして大量の給与計算が実行されても、reader を上手く活用して writer の負荷を抑える構成が実現できました!
この先
LWF 100%適応してから、昔発生した給与計算の大量 enqueue による CPU 負荷向上の alert はほとんど上がらなくなりました。 かなり効果を実感しています。
また、今回 LWF を利用したことにより、給与計算 Job 1 回の実行時間が想定通り少し遅くなりました。 前述した通り writer instance に生まれた余裕を給与計算 Job 用 replica を増やすことで利用し、ユーザーの給与計算待ち時間を短縮する予定です。 インフラの負荷軽減で終わらず、ユーザー価値向上まで繋げたいと考えています。