
こんにちは、会計チームでエンジニアをやっている ut (@utdoi1) です。最近はレポート周りの開発を主に担当しています。
先日あった機能リリースにおいて、大量のデータを対象とした移行タスクを実行する機会がありました。
タスクの概要としては、freee会計に登録されている事業所1つごとにデータ移行をしていくものでした。
今回はfreee会計にアカウントを作成している全ての事業所に対してタスクを流す必要があったため、普通に実行していたら完了までいったい何日かかるのか分からないくらいの規模感でした。
そのため、並列実行も考慮に入れて割としっかりめに実行計画を立てて臨みました。
この記事では、その実行計画を立てた時の作業の流れと、それぞれの過程における細かい作業内容を紹介します。
計画策定までの流れ
全体としては以下のような流れで作業を進めていきました。
- タスク実行時間に関係するデータの度数分布表を作る
- タスク実行時間に関係するデータの量と実行時間の散布図を作る
- 度数分布表と散布図を元に一括タスク実行の範囲から除外する事業所のデータ量閾値を決める
- 検証用環境と本番環境でタスクの実行時間を比較し、spec 差を考慮するための係数を算出する
- ヒストグラム/散布図/spec係数に基づきタスクの延べ実行時間を見積もる
- 検証用環境で並列にタスクを流してみて、DB負荷を確認する
- 並列数で想定延べ実行時間を割り、どの並列数ならどれくらいの時間でタスクを流しきれるかシミュレートする
- DBの具合とシミュレート結果をもってDBREに相談し、実行に不安のない並列数を確定させる
- 確定した並列数を元に実行スケジュールをfixさせる
以下、それぞれの作業の詳細について書き記していきます。
タスク実行時間に関係するデータの度数分布表を作る
実行するタスクで行う処理にかかる時間は、その事業所のとあるテーブルのレコード(データAとする)の量に大きく左右されるものでした。
データAの量は事業所によって結構バラツキがあり、計画を立てる上でもまずはそのざっくりとした分布を把握しておきたいと考えました。
分布を確認するために、こちらの記事 を参考にして redash でクエリを書いて度数分布表を作っていきました。
分布としてはデータAの量が少ない方に偏りがあるものの、ちらほらデータAの量が飛び抜けて多い事業所もいたりしたため、固定の階級数で1つだけ表を作るといまいち詳細な分布が見えてきませんでした。
そのため、度数が集中している階級に対してドリルダウン的にクエリを書き度数分布表を追加で作成していくようにすることで、より詳細な分布が把握できるようにしました。
最後に各クエリの結果をまとめて作った度数分布表(イメージ)
| データA量の範囲 | 該当事業所数 | 全体に対する割合 |
|---|---|---|
| 92,693〜926,922 | 19 | 0.00% |
| 9,568〜92,693 | 933 | 0.14% |
| 1,000〜9,568 | 18,403 | 2.83% |
| ... | ... | ... |
タスク実行時間に関係するデータの量と実行時間の散布図を作る
データAの量がタスクの実行時間に関係してくること自体は分かってるとはいえ、実際両者にどのような関係性があるのかは事前にざっくりと見ておきたいです。
線形関係だと思ってたら実は2乗に比例するような非線形の関係だったりしたら困るし、線形だったにせよどれくらいの傾きなのかを知っておくと安心です。
また、それぞれの階級に属する事業所でタスクを流すのにざっくりどれくらいの時間がかかるのかが分かっていると、総実行時間の見積もりを加重平均っぽくいい感じに出せます。
そのため、各階級においていくつか実行時間をサンプリングしつつ、それらを散布図にプロットしていくことにしました。 先程作成した度数分布表の各階級に属する事業所をいくつか pick し、それらに対して検証用環境で実際にタスクを実行してかかった時間を計測しつつ、それぞれの持つデータAの量を出して図表に落とし込んでいきました。
作成した散布図(イメージ)
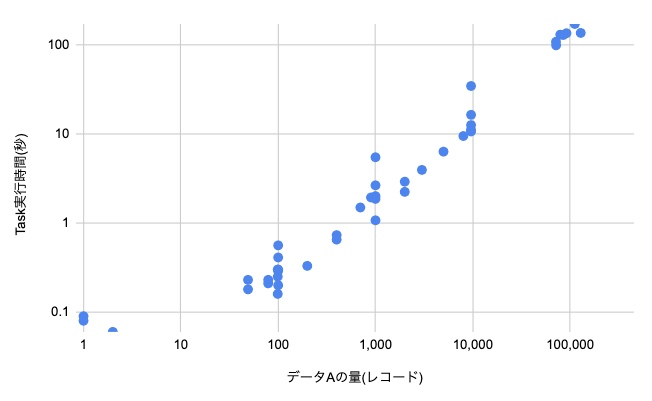
度数分布表と散布図を元に一括タスク実行の範囲から除外する事業所のデータ量閾値を決める
度数分布表を見てもらえると分かるとは思いますが、データAの量の分布は少ない方に大きく偏っていました。 大半が レコード数 1000 以下で、そこに 10000 以下の事業所がすこし、さらにそれ以上の極端に量が多い事業所(いわゆる大規模事業所)がごく少数あるような分布です。 また、大半を占める レコード数 1000 以下の事業所に対して、極端に量が多い事業所ではタスクの実行時間に100倍近くの開きがありました。
そのようなバラツキがある集団に対してまとめてタスクを実行すると、並列実行を想定した場合結構困ります。 並列実行を行う各タスクで対象とする事業所群をかなり慎重に選ばないと、実行時間に大きな偏りが出てしまい(pod A は5時間で終わったけど、pod B は大規模事業所が含まれていたため 8 時間もかかった)せっかく立てたスケジュールが運次第で破壊されてしまいます。 そのため、不確定要素となりうる大規模事業所はいったん並列実行の対象からは除外しておいて、後でまとめて流す戦略を取りました。 1つ1つは時間がかかるとはいえ数はそこまで多くないので、後でそれらをまとめて流すほうがスケジュールは立てやすくなります。
上述の度数分布表や散布図を元に、大規模事業所の基準となるデータAの量の閾値をいくつにするかを話し合い、今回は 10000以上 と決めました。
検証用環境と本番環境でタスクの実行時間を比較し、spec 差を考慮するための係数を算出する
ここまで見てきた度数分布表や散布図は、あくまで検証用環境でのタスク実行時間を元に作成したものでした。 しかし検証用環境と本番環境では結構な spec 差があるので、実際の実行時間を見積もる上ではそれを加味する必要があります。 とはいえ本番環境で先程のようなサンプリングを何回も行うわけにはいきません。
そのため検証用環境での実測値ベースで算出した想定実行時間に対して調整用の係数をかけることで、本番環境での想定実行時間を近似しようと考えました。 具体的には、少数の同一事業所(本番環境でも先んじてタスクを流してよい事業所をいくつか選定しました)に検証用環境と本番環境それぞれでタスクを流し、それらの実行時間の比を調整用係数として使うようにしました。
ヒストグラム/散布図/spec係数に基づきタスクの延べ実行時間を見積もる
ここまでの情報を元に、全事業所を対象にタスクをかけた時の想定延べ実行時間を算出しました。
度数分布表や散布図作成に使用したサンプリング結果があったので、各階級ごとに重みづけを変える感じで実行時間を計算しました。 計算式としてはざっくり以下のような形です。
として
ここの代表値についてはいくつか候補(最大値、最小値+最大値/2など)を出してそれぞれにおいてスプシでシミュレーションを行い、どれくらい見積もりを悲観的にするかなどを考慮し、最終的に最小値+最大値/21を選択しました。
検証用環境で並列にタスクを流してみて、DB負荷を確認する
想定延べ実行時間を算出した結果、直列実行だとあまりに時間がかかりすぎて予定していたリリース日から大幅に遅延してしまいそうだったので、タスクは並列で実行したいと考えました。 とはいえ DB に結構負荷のかかるタスクなので、あまりに並列数を増やすと割と危険かなと思い事前に負荷を予測しておくことにしました。
検証用環境で実際に並列にタスクを流してみて DB のcpu使用率や IOPS などを Performance Insights や Cloudwatch にて確認し、並列数に応じて負荷がどれくらい変わるのかを計測しました。
並列数で想定延べ実行時間を割り、どの並列数ならどれくらいの時間でタスクを流しきれるかシミュレートする
また、想定延べ実行時間を並列数で割る形(事業所当たりの実行時間が均等に分散するようにタスク実行対象の事業所を選ぶ想定)で、どの並列数ならどれくらいの時間でタスクを流しきれるかをシミュレートしました。
単純に並列数で割るだけでなく、流石にタスクを1日中流しっぱなしは無理だろうという想定でタスクを流せるのは1日8時間(夜の間)と仮定し、その場合カレンダー的に何月何日ごろにタスクが完了しそうかまで見積もっておきました。 メンテが途中に挟まってきた場合などを考えると、タスク実行開始日から算出した日数を単純に足した予定よりも大きく後ろ倒しになってしまう可能性があるためです。
DBの具合とシミュレート結果をもってDBREに相談し、実行に不安のない並列数を確定させる
どれくらいの並列数でどれくらいDBに負荷がかかるのか、またどれくらいの並列数だとどれくらい総実行時間がかかるのかが分かったら、それらのデータを元にfreeeのサービスでのDBの安定運用を専門としているDBREチームに相談し、並列数のいい塩梅を決めました。
ロック競合についてなど自分たちだけでは見落としていた観点について指摘を受けることができたので、相談してみてよかったです。
確定した並列数を元に実行スケジュールをfixさせる
ここまで確定したら実行スケジュールを決めきることができます。 何月何日の何時から何時までに、どれくらいの事業所に対してタスクを流し、計何日間でタスクを流し切るかの具体的な計画を立てていきます。
DBには結構負荷のかかるタスクなので、今回は平日深夜or土日にタスクを実行することを前提にスケジュールを立てました。
最後に
事前にしっかりと計画を立てたかいあって、大きなスケジュールズレもなくタスクを流し切ることができました。 規模が大きく直感的には実行時間の読めないデータ移行タスクでも、ちょっとした統計学の技法を使うだけである程度信頼できる計画を立てることができると分かったのは大きな収穫でした。
大規模なデータ移行を伴うようなPJではエイヤでタスクを流してしまうのではなく、一瞬立ち止まって冷静に実行計画を考えてみると幸せになれそうです。
-
統計的にはあまりよろしくない値ですがサンプリング事業所数を増やしてまともそうな値を選んでる暇もなかったので↩