
この記事は freee Developers Advent Calendar 2024 の 22日目のエントリーです。
こんにちは、PSIRTでtech leadをやっている eiji です。冬にモヒート作ろうとしたらライムが手に入らず、柑橘類だから秋から冬にとれるはずでは? と調べたらライムは四季咲きだそうです。もしかして、ここでも買い負けているということ?
TL;DR
Redisのnetwork帯域を使い果たして自滅する話 です。
RedisをCacheとした構成
Redisをcacheとして用いた構成は、ごくありふれたものだと思います。
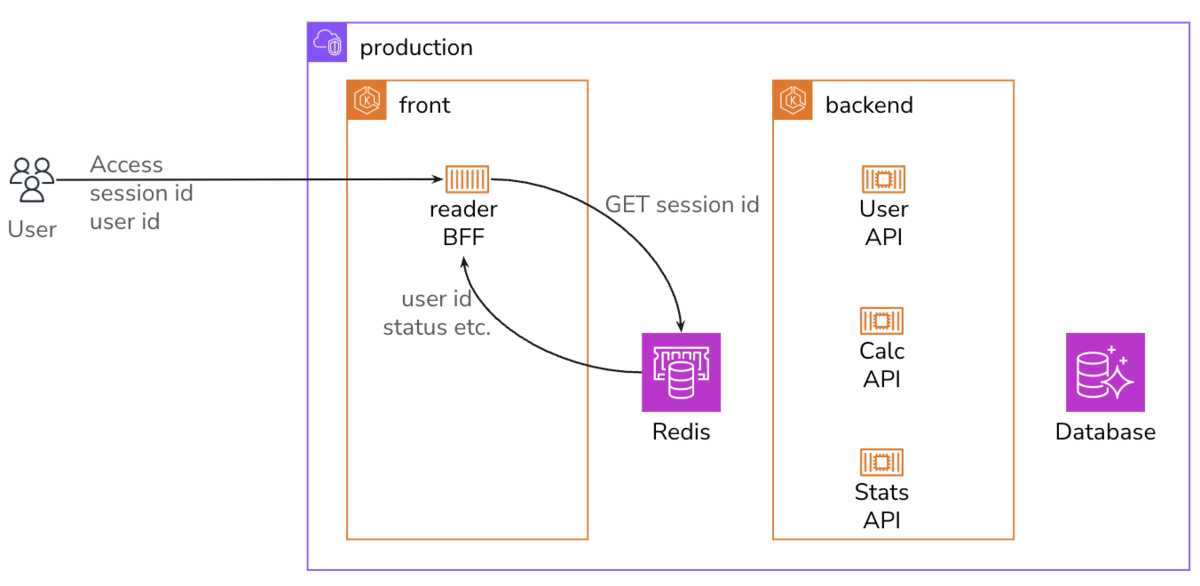
session IDに対応するuser IDと各種statusを返してもらって処理をする、といった感じです。 user IDはbrowser側からcookieやheaderで送付してもらって、Redisから取り出してきたuser IDと照合するのも大切です。
sessionのcache data sizeは8KBで、8時間でexpireする仕様だとして、その間の新規session数が10,000 sessionsくらいだとすると、必要なmemory sizeは、
8KB * 10,000 = 80MB
あ、こんなもんなんだ。Redisだとrecord expireも仕掛けられるし、楽で良いよね。 Redisの料金表を見てみると、一番小さくて安いcache.t4g.microでも500MiB保存できるので、それで良さそうです。

突然のRedis停止
順調に運用を行っていたある日、突然サービスへのログインがほぼできなくなる障害が発生しました。 ログを見てみると、どうやらRedisへのアクセスがtimeoutしているようです。
では、Redisに障害が発生したのか?と疑ってみましたが、management consoleで見る限り、正常に動作しています。
さて、当初は、単純なsessionだけをcacheしていたRedisですが、この時点ではuserやadminさまざまな情報をcacheするように拡張され、responseの平均サイズは32kBまで拡大していました。

しかし、それでも、Redisのメモリには空きがありますし、ネットワークの最大帯域5Gbpsには達していません。 一体、何が障害の原因なのでしょう?
Network bandwidth の baseline と burst と allowance exceeded
色々探し回った結果、CloudWatchのmetricsで異常な値となっているものが見つかりました。 CloudWatch→Metrics→All Metrcsにアクセスし、 ElastiCacheとAllowance、そして障害が起きているRedisの名前で検索をかけると、以下の4つが表示されますが、
- NetworkBandwidthInAllowanceExceeded
- NetworkBandwidthOutAllowanceExceeded
- NetworkConntrackAllowanceExceeded
- NetworkPacketsPerSecondAllowanceExceeded
この中の、 NetworkBandwidthOutAllowanceExceeded が以下のように盛大に発生していました。

NetworkBandwidthOutExceededとは、どういったmetricsなのでしょう?AWSの資料によると、以下のような説明がされています。
アウトバウンド集計帯域幅がインスタンスの最大値を超えたためにキューまたはドロップされたパケットの数。
ここで、キュー = queueingやドロップ = dropについて、考えてみたいと思います。
ネットワーク上の回線の帯域幅 = bandwidthは、回線ごとに異なります。 以下の図では、左から右に向けて通信が行われていますが、途中に帯域幅が狭くてbottleneckとなる箇所があるとします。

もしも、packetを受け取った回線よりも、送信しようとしている回線の帯域幅が狭ければキューに貯めて(queueing)、少し遅らせてから送付しようと努力します。

障害発生時には、完全にRedisとの通信が遮断されたわけではなく、一部は疎通していたのですが、200ms弱のdelayが生じていました。
しかし、送信しようとしている回線の帯域を超えるpacketが定常的に届くと、queueingしていたpacketの一部を捨ててしまいます。

そのうち、TCPの仕組みで送信する速度が抑えられるのですが、あまりに帯域が絞られてしまうとRedisの通信がtimeoutする状況に陥ります。
え? 5Gbpsには達していないのに、なぜdropされるの?と思うかもしれませんが、あくまで最大5Gbpsが利用できるのであって、定常的に最大帯域で通信できるわけではありません。ElastiCache Redis OSSでサポートされているノードの詳細を見てみると、

t4g.microのベースライン帯域幅は、0.064Gbpsです。つまり、
cache.t4g.micro 0.064 Gbps = 64 Mbps = 8 MB/s
8MB/sが定常的に利用できる帯域です。この帯域で32kBのresponseをいくつ処理できるかというと、
8MB/32kB = 250
250個です。あるsessionを処理するために、frontとbackendで別々にRedisを利用していたり、他の機能の処理でRedisを利用していれば、帯域がどんどんなくなっていきます。
つまり、ネットワークの帯域幅のこと考えずにRedisを利用し、AWS VPCの中で自ら増幅攻撃を行った結果、ネットワーク帯域を使い果たしていたのですね。
ちなみに、EC2 instanceにもネットワーク帯域幅の制限は存在します。たとえば、EC2 instance t4g.micro typeのネットワーク帯域幅は、Redis OSSノードと同じくbaseline/burst = 0.064Gbps/5Gbps です。
前もって気づけるのか? 起こってしまったらどうしたら良い?
では、networkがヤバイことにもっと早めに気づくにはどうしたら良かったのでしょうか?
CPUもt2以外のburst可能なinstance typeであれば、CPUCreditBalanceやCPUCreditUsageといったmeticsを参照することで、creditを使い尽くす前に対処を行えばCPU性能が下がってしまう事態を避けることができます。
しかし、残念ながらnetwork creditの状況を教えてくれるmetricsは、提供されていません。
なので、不幸にして、以下のようなNetwork * Allowance Exceededが1回発生してるグラフを見つけたりすると、ヤベーと焦るかもしれません。

でも、間欠的に1回生じているだけならば、問題ありません。これは、マイクロバーストと呼ばれる現象だと思われます。 詳しくは以下を参照してほしいのですが、 repost.aws
networkの帯域制限は、単位時間あたりのデータ量を逐次計算し閾値よりも多ければqueueingする、という処理を行うものなので、たまに観測した単位時間あたりのbinの中のデータが多くなり、queueingが生じることはあり得ます。
Network Bandwidth In/Out Allowance Exceededが生じたとしても、その数が少なければ、以下のいずれかの処理が行われるだけです。
- queueingした後で送信 → 200ms以下のdelayが発生する
- queueing → packet drop → TCP再送処理
サービス全体への影響は軽微で、ほぼ無視して良い類のものだと思います。
しかし、Network Bandwidth In/Out Allowance Exceededが継続的に発生し100や200を超え、Redis timeoutが生じる状況なのであれば、requestもしくはresponse sizeを小さくするか、より大きいinstance typeへの変更が必要です。
Network Conntrack Allowance Exceededが生じた場合、Redisに接続しているconnection数が多すぎるので、connection数を減らす必要があります。 ElastiCache Redis OSSノードが扱えるconnectionの最大数は65,000です。 多数の接続 (Valkey と Redis OSS) - Amazon ElastiCache
Network Packets Per Second Allowance Exceededが生じた場合、単位時間あたりに処理できるpacket数の限界を超えているので、request数を減らす必要があります。たとえ帯域幅に余裕があるとしても、小さなrequestやresponseを大量にやり取りすると、この制限に抵触してしまいます。
ちなみに、instance typeごとのpps = Packets Per Second [packets/sec] の値を記した公式の資料は、ありません。 正確な値を知りたければ、各環境でiperfを用いて計測する必要があります。
instance typeを大きいものにすると基本的にはこなせるppsも増えるけど、512bytes 以下の short packet だとburstしたとしても最大bandwidthは無理かもね。ENA expressを利用すればlatencyが93%良くなるみたい。など、他にも気にするべき点はありますが、今回はここまでにしておきます。
終わりに
CPUとRAMだけでなく、networkのことも考えてsizingしてほしい。 network allowance exceededを正しく怖がりましょう。
モヒートに使うラムは、habana club 3年でお願いします。
明日は、エンジニアリングマネージャーのsentokunの記事です。
補足
本番にt系のinstanceを使うことはないと思います。フィクションです。 でも、それとは関係なくnetwork allowance exceededを気にしていない人は多いと思うので、注意してね。