

はじめに
この記事は freee Developers Advent Calendar 2024 - Adventar 12/14(14日目)の記事です。
こんにちは。freeeで機械学習エンジニアをしているmickyです。 普段はAI-LabというチームでOCR開発のリードをしています。 今回はOCRチームで今期にかけて開発したクレジットカード明細OCRについて概要と技術的なチャンレンジについて紹介します。 このクレジットカード明細OCRはfreeeのデータ化サービスの内部プロダクトに搭載され、実業務で使用される予定です。
freeeのデータ化について
freeeデータ化サービスとは、お客様からレシートや領収書、通帳といった証憑データをfreeeがお預かりし、 1~2営業日で仕訳データとして納品するサービスです。 これにより、freee会計の取引登録を圧倒的にラクにする「自動で経理」が活用できたり、結果をCSV出力することで他社の会計ソフトへインポートしたりすることが可能になります。
データ化チームでは、多くの証憑から人力で情報を抽出し、システムに入力していますが、証憑の数は膨大で、入力コストが高いのが現状です。
領収書や請求書、通帳にはOCRサポートがあり、入力コストは軽減されていますが、クレジットカード明細についてはサポートがなく、コストがかかっていました。
今回、AI-Lab、データ化システム開発チーム、オペレーションチームが一体となってクレジットカード明細OCRの開発と運用に取り組みました。

クレジットカード明細OCRについて
まず始めにクレジットカード明細について説明します。 クレジットカード明細は、クレジットカード会社がカード利用者に対して発行する取引の記録です。通常、毎月一度、紙媒体や電子メール、オンラインバンキングを通じて送付されます。この明細には例えば以下の情報が含まれています:
- 取引日: 各購入が行われた日付。
- 加盟店名: 商品やサービスを購入した店舗や企業の名前。
- 利用金額: 各取引ごとの支払い金額。
- 総利用額: その月における全体的な使用金額。
- 支払日: 次回の支払いが必要な日付。
- 最低支払額: リボルビング払いなどを利用している場合の最低限支払うべき金額。
- ポイント情報: 獲得したポイント数や使用可能なポイント残高など。
これらの情報のうち、データ化サービスでは取引日、加盟店名、利用金額を人目でチェックして仕訳データに変換します。
ここから今回開発したOCRの概要と詳細について説明していきます。 クレジットカード明細OCRは入力となったクレジット明細のpdfファイルや画像から、一連の取引記録の各取引日、加盟店名、利用金額を抽出し、呼び出し元に返却するマイクロサービスとなっています。 これらの抽出したい情報は、明細上で表形式になっていることがほとんどで、各社様々なフォーマットで発行されている明細からいかにこの表を検出し、そこから取りたい情報を抽出するかが開発のポイントになってきます。
これを実現するために、いくつかの方法を検討しました。
table detectionの利用
document intelligenceの分野では、書類等の画像から表部分を検出する手法の研究が従来から行われています。 当然これらの技術を利用することがまず頭に浮かびました。 Google Cloudでは、この技術をAPI経由で簡単に利用できる機能がすでに備わっており、検出された表のカラムやセルの情報をjson形式で取得することができます。
この機能を使って手元のいくつかのサンプルを試しましたが、結論としては上手く機能しませんでした。クレジット明細の取引履歴の表は情報量が多く、各カラムを表す文字が隣接しているため、別々のカラムとして認識させたい部分が1つのカラムとしてマージされてしまうことが多々ありました。結果として、そのままカラムとして使用するのが難しい認識結果が得られました。
ルールに基づいてカラムを分離する方法も検討しましたが、カラムの順序やフォーマットが各社異なるため、かなり手間がかかることが予想されます。したがって、この方法は断念しました。
vision and language modelの利用
近年のLLM(大規模言語モデル)の発展により、画像を入力できるモデルが増えています。このマルチモーダルなLLMは、書類などのOCR用途としても注目されています。
検証時に、OpenAI GPT-4 VisionやClaude3のHaiku、Sonnet、Opusなどを使用して、クレジット明細の画像から情報を抽出できるか試みました。しかし、結論としてこの方法も効果的ではありませんでした。クレジット明細は文字数と情報量が多いため、LLMが生成した表の情報には多くのハルシネーションが含まれ、実用には適しませんでした。
OCRされたテキスト情報+LLM
最終的にこの方法を採用しました。通常のOCRで取得した画像上のテキスト情報をLLMの入力として使用し、LLMにそのテキストから表形式の情報を抽出させます。最初はうまくいくか半信半疑でしたが、最近のLLMは非常に優れており、生の文字列をそのまま入力しても必要な表情報をかなり正確に出力してくれました。OCRされた文字を入力しているため、ハルシネーションはほとんど発生しませんでした。最近の研究でも、書類のOCRはE2E(エンドツーエンド)で行うよりも、一度OCRされたテキストを使う方が精度が高い傾向があるようです。
精度については、各社のフォーマットによる差異はありますが、平均で約90%以上の正確さを確認し、入力時間を70%以上削減できることがわかりました。
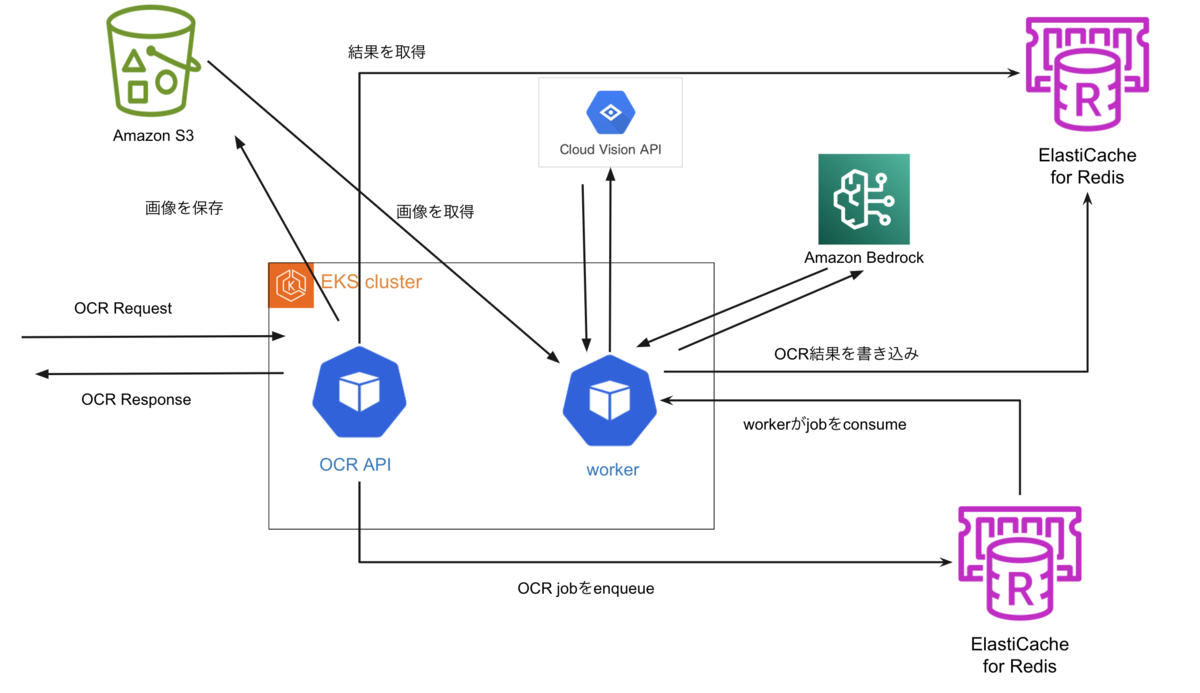
アーキテクチャ
freeeでは、基本的にサービス構築にはAWSを使用しています。今回のLLMサービスとしては、AWSが提供しているBedrockを採用しました。これは、AWS環境内で完結して利用できることや、ログ機能が標準で備わっていることが理由です。
このOCRマイクロサービスはREST APIとして構築され、バックエンドではPython製のCeleryを用いた非同期アーキテクチャを採用しています。
技術的なチャンレンジ
今回無事リリースまでこぎつけましたが、これで開発が終わりというわけではありません。 まだまだ解決しなければならない課題が残っています。
ハルシネーションの低減
OCRされたテキストを入力とすることでVision language modelよりはハルシネーションする確率は低いですが、全くしないというわけではありません。 今は単純にプロンプトで表を抽出するように指示しているだけですが、prompt engineeringのテクニックによる精度向上や実際に出力が明細上に存在するか確認するようなgroundingのような手法を検討していきたいと思っています。 これを実現するために評価データセットを充実させたり評価パイプラインを整備するなどのLLMOpsも必要になってきます。
クォータやratelimitへの対応
LLMサービスとしてAWSのBedrockを使用していますが、やはり需要過多のため、クォータやratelimitが厳し目です。 OCRのリクエスト数によってはこれらの上限に引っかかってしまう可能性も十分あるため、今後は上限にあたった場合に軽量なモデルや別リージョンのモデルにフォールバックするなどの対応を入れていきたいと思っています。
終わりに
このクレジットカード明細OCRのプロジェクトは、私がデモアプリを作成し、オペレーションチームのマネージャーに試用してもらい、その有用性を確認してもらったことから始まりました。実際のリリースに際しては、AI-Labのチームメンバー、プロンプト開発チーム、オペレーションチーム、さらにSREやPSIRTから多大なサポートをいただきました。
このリリースが開発の終わりではなく、実際に運用しフィードバックを受けながら、オペレーションをより簡素化できるように継続的に開発を進めていきたいと考えています。