
大阪Ruby会議に参加しました!
こんにちは、関西でfreee販売・freee工数管理の開発を行っています、bucyouこと川原です。 2024/8/24(土)に開催された、大阪Ruby会議04にスポンサーとして (かつ個人的にも気になったので) 参加してきました。
同僚で大阪Ruby会議04の運営を行っている hachi さんから、ぜひ参加してほしいとのことで声をかけられ、 新たな知見を求め弊チーム総出で業務として参加したのでした。
そもそもRubyを触り始めたのは freee に入ってからという方もいれば、カンファレンス自体参加が初めて という方もいるという状態だったのですが、チームのモチベーションが上がるイベントで非常に良かったです。
個人的な感想としては、なぜか構文解析の内容がもりもりで、非常に歯ごたえのある内容で美味しかったです。 自分の中では Minify Ruby Code が非常に刺さりました。 (役に立つかはわからないが) 技術的な思考の過程と、最終的にそれを rubocop の開発に使えるのでは? という発見が素晴らしいと思えました。
おそらく、翌週あたりに、Ruby初心者から見た大阪Ruby会議04について別のレポート記事が上がると思いますのでお楽しみに!
Sponsor LT 「データベースだけじゃないN+1とその対策」について
ありがたいことに、5分ほどお時間をいただいたので、スポンサーブースの紹介のついでに 最近の Ruby on Rails 開発での試みを、もともとチーム向けの資料として作ったものを発表することにしました。

freee販売という製品を開発しているのですが、社内では屈指のプロダクト連携を重視する製品となっています。 連携先によっては、WebAPI (gRPC, RESTなどなど) で提供されており、あらかじめデータベースからN件の情報を取得し、 それに関連する情報を連携先から取得したいという状況の場合に、単純な実装で済ませてしまうと N+1 を発生させてしまう という課題を抱えます。
ということで私たちは、WebAPI によって起きる N+1 対策として「設計」でなんとかしようとする対策 (攻め) と、 起きてしまったときの「ガード」を作る対策 (守り) の2つに取り組んでいます。
設計でなんとかする (攻め)
要件を整える際に外部リソースをどのように扱うかという方針を整えましょう! という話です
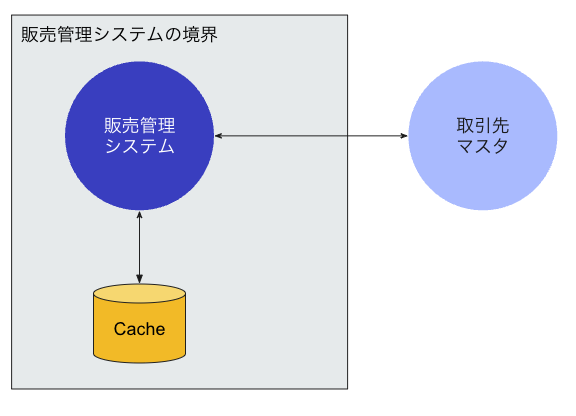
キャッシュ利用
キャッシュがないときはN+1に対して無力だが、WebAPIが一括取得に対応していない場合や、リクエスト量が多い状態でレスポンス速度を上げたい状況下では有効な手段であると言えます。 後続の、外部システムの情報更新をトリガとしてキャッシュに情報を乗せるというしくみと組み合わせても良いかもしれません。
Lazy Load
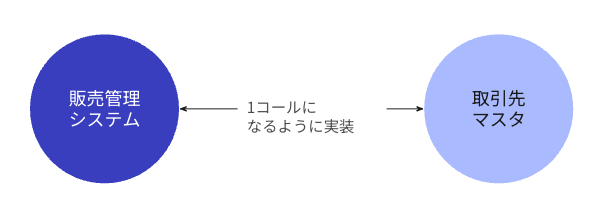
複数の取得処理が発生した時に、いったんリクエストを発生さぜず、利用するタイミングになったらWebAPIコールをまとめ1回だけ発生させるコードを用意するという方法です。 GraphQL の実装などで使われるようですが、設計を意識する中で Repository の機能として使える要素でもあります。 私たちは、batch-loader gem をこの機構を実現するために利用しています。
class SalesListDto # 省略 def customer # 取得時はあまり意識しない partner_repository.load(customer.id) end end class PartnerRepository def load(id) BatchLoader.for(id).batch do |ids, loader| # [{id => Hash}, {id => Hash}] のような形式で返されるものとする PartnerClient.fetch(ids).each {|k, v| loader.call(k, v) } end end end # Repository から集約たちをとってくる sales = sales_repository.search(query) # DTO作る sales_list = sales.map { |s| SalesListDto.new(sales: sales) } # このタイミングで初めて、PartnerRepository からまとめて情報が取得される sales_list.first.customer&.name
batch-loader 自体の実装は非常にシンプルなものとなっているため、仕組みを読んでみるのも面白いかもしれません。
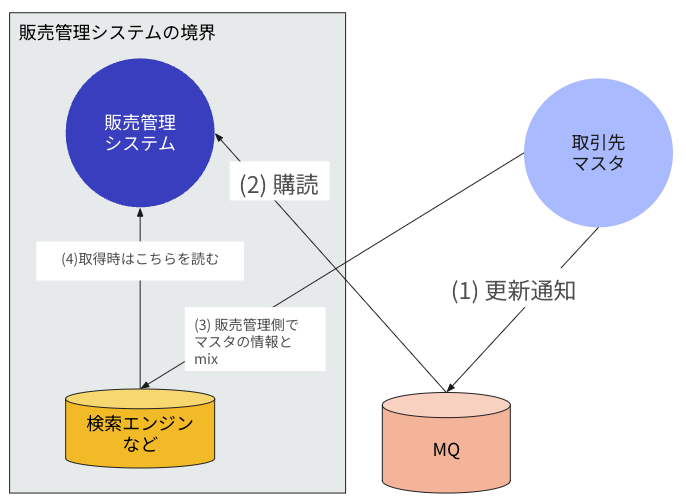
事前にデータを用意
外部システムの情報更新をトリガとして、検索エンジンの情報を更新をかけてそれを利用するという方法です。 これをやるために Message Queue などを用意することが大抵の場合は求められるので、やや高価ではありますが、 外部システムの情報を元に検索ができるといった要件があるのであれば、この方法を取ったほうが良さそうではあります。
ガードを作る (守り)
rspec の webmock で検知できる仕組みを用意する
この仕組みは rspec 実行時に、webmock を利用している時に有効です。
RSpec.shared_context '過剰なAPIコールを制限する' do let(:max_api_calls) { 1 } after do api_calls = Hash.new(0) WebMock::RequestRegistry.instance.requested_signatures.hash.each do |signature, num| path_without_parameters = signature.uri.omit(:query).to_s.gsub(/\/(\d+|[0-9A-Z]{26})(?=\/|$)/, '') method = signature.method.to_s expect(api_calls[method + pathwithout_parameters] += num).to be <= max_api_calls end end end RSpec.configure do |config| # api: :mock config.include_context '過剰なAPIコールを制限する', api: :mock end
丁寧なテストを心がけるのであれば、webmock それぞれでコール回数を制限するのが良いのですが、万が一取りこぼした場合に助けられるコードとなります。
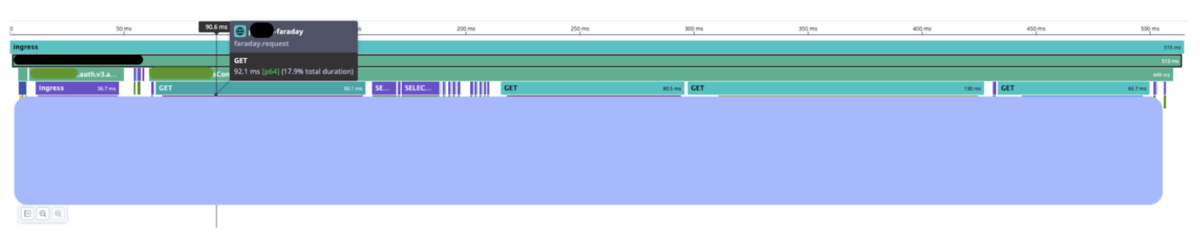
APMで問題を掴む
ここまでいろんな策を重ねていたとしても、いざ実環境で動かしてみると万が一ということはありますし、遅いリクエストが発生したとに足がかりとなる情報が必要です。 もしDatadogなどを導入しているのであれば、外部通信をトラッキングできるようにしておきましょう!
まとめと次
そんな普段の業務の話をしたのでした
今回の雰囲気的には、もうちょっと技術で遊ぶ話をしてもよかったかな〜という感触があったので、 次回の機会があるならば、もうちょっと役立つかわからないトークとかをしようと思いました。
freee 関西オフィスが会場提供をしている、Kyobashi.rb がそのうち開催されるはずなので なにか仕込もうと思ってます。 関西でRubyと親しんでいる方は (そうでない方も) ぜひお越しください!!