
この記事はfreee 基盤チーム Advent Calendar 2023 の23日目の記事です。
23日目の記事なのに、現在の時刻は12/23 23:55です。 PSIRT*1のeijiです。
もしもの時に備えてログを取りまくり、事が起きればログの海に溺れる毎日ですが、今年もいろいろありました。
TL;DR
もしもの時のために、AWS上で「ログを保存する」、「ログを解析する」を整理しておきます。
前置き
freeeでは、毎年新人の皆さんにHardeningを実施しています。 flagを見つけたら点数を稼げるCTF*2とは異なり、incident responseを模したHardeningでは脆弱性を修正しただけでは評価されません。 freeeでのHardeningは、一言で言うと、容赦ない攻撃を受ける中で脆弱性を含むsystemを如何に修正しつつ運用するかというゲームだからです。
Hardeningに先立って「ログを取っておこうね。そうしないと何が起きて、どこまで被害を受けているのかわからないよ!」と、何度も念を押しているのですが、毎年以下のような状況が起きています。
- 実際に攻撃を受けて、自分たちのsystemが502 Bad Gatewayを返すまで気付けない
- metricsを見ていてRTTが伸びているとか、HTTP response statusに4xxや5xxが増えていることには気付けても、どのrequestに対して発生しているのか、どこからのaccessについて発生しているのか、分からない
- datadogの綺麗な画面上でログを探してみるが、目当てのログが存在しないか、元のlogがJSONではないためsearch queryがかけす、手が止まる
- そもそも、ログってどこにあるのでしょう?
こうした状況は、実際の障害対応、incident responseの現場でも起こり得ます。そうならないために、前もってログを保存する方法、および、ログから情報を引き出す手段を雑多に並べておきます。
オンプレミス環境でログを保存する
手元やオンプレミスでlinux serverを運用していたり、VM host、EC2 instance でhostを構築している場合は、
以下のようなログを/var/logで収集していました。
www access log
apacheが、/etc/httpd/conf/httpd.confなどで出力先を設定しているログです。
- アクセスログ
- /var/log/httpd/access_log
- エラーログ
- /var/log/httpd/error_log
nginxだと、/etc/nginx/nginx.confなどで出力先を設定してましたね。
- アクセスログ
- /var/log/nginx/access.log
- エラーログ
- /var/log/nginx/error.log
PHP-FPMを利用してPHPを動作させている場合だと、/etc/php-fpm.d/www.conf などで出力先を設定していました。
- エラーログ
- /var/log/php-fpm/www-error.log
syslog
rsyslog https://www.rsyslog.com/ が、 /etc/rsyslog.confや/etc/rsyslog.d で出力先を設定しているログには以下のようなものがありました。
- systemの一般的なログ
- /var/log/messages
- /var/log/syslog
- 認証ログ
- /var/log/auth.log
- /var/log/secure
audit log
それから、audit logとして、全てのcommandの実行履歴をとったりしていました。
ubuntuだと、auditd をinstallして、
apt-get install auditd audispd-plugins
/etc/audit/rules.d/audit.rulesに以下を追記して、
-a exit,always -F arch=b64 -S execve -a exit,always -F arch=b32 -S execve
systemctl restart auditdで反映させて、以下を取得していました。
- audit log
- /var/log/audit/audit.log
さらに、ssh accessした際のconsole logを保存したりとかも行っていました。
logrotate
ここまでの設定だと、一つのlog fileに永遠に書き続けてしまうことになるので、rotateする設定も行なっていました。 dailyやweeklyでそれまでのlog fileを別名に変えて、rsyslogをreloadしたりすることで、新しいlog fileへの切り替えをしてましたね。
でも、defaultの設定だと4週間ほどしかlogを保持しません。古いものはどんどん消し込まれています。
基本的には、ログはかけがえの無い資産なので、永遠に保持しておきたいところです。 となると、他のstorageにbackupをとったり、remoteのsyslog serverに飛ばしたりといった整備が必要です。
この辺りは定型作業なので、統一してしまいたいところです。
EC2 instanceを利用したsystemでログを保存する
オンプレのserverの仕組みをあまり変えずに、AWSのmanaged serviceを組み合わせて構築すると、以下のような構成になると思います。
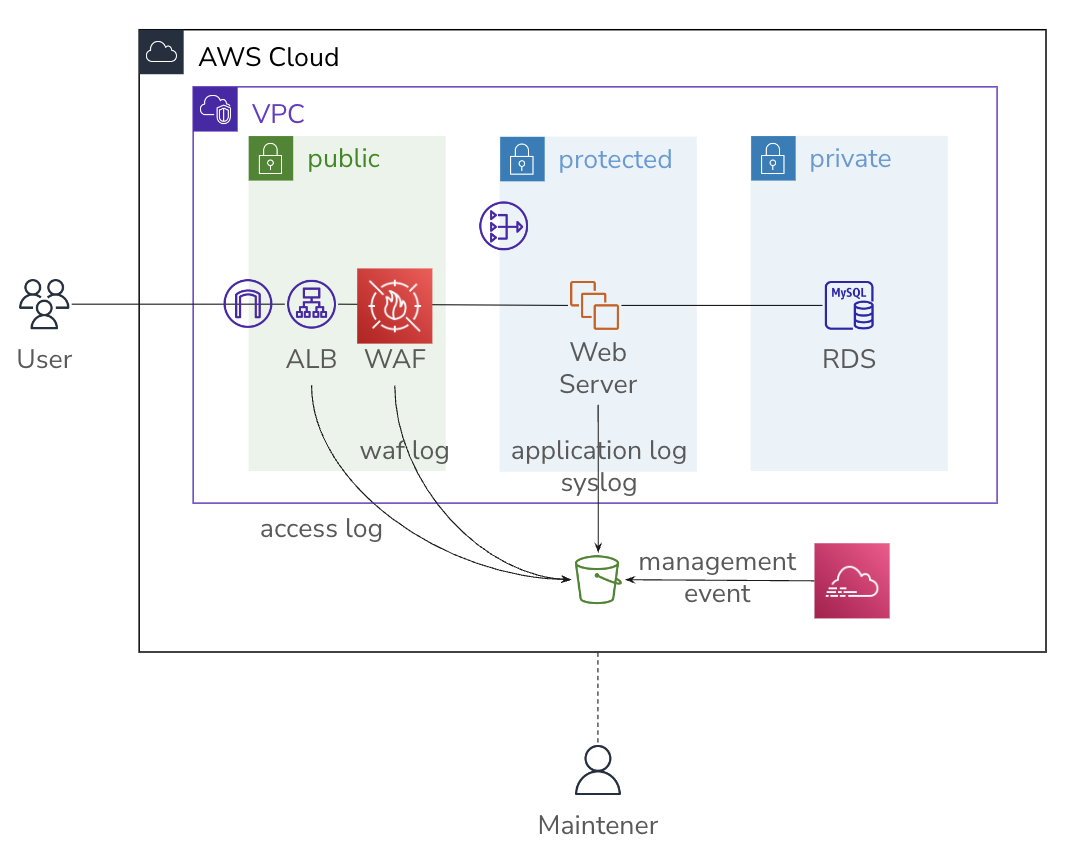
AWS上では、s3 bucketに全てのログを集めるのが鉄則です。
間違ってもdatabaseにログを保存してはいけません。障害対応の時に事象の確認がsql queryで行われていたり、rails cしてからfind...しないとuserの行動がわからない。という状態なのであればapplicationが出力するログが不足しています。 database内のrecordは新しいrecordで上書きされてしまうかもしれません。sql query logを残しておいたとして、userやsystemの処理との結び付けが間違いなく行えるでしょうか? さらに、truncate tableやdrop databaseで簡単に消えてしまう*3かもしれません。
S3 bucketを作る
悪いことは言いませんから、ログはs3 bucketに保存しましょう。
- versioningは有効にしましょう。
- 世代は永遠に保持しましょう。deleteされたとしても、それすらもhistoryに残ります。
- DeleteObject権限はごく限られた人にだけ配布しましょう。
- DeleteObject eventが発生したら、alert発報しましょう。
- cross accountでlog bucketにアクセス可能性があるのであれば、bucket ACLを無効化しobject ownerをbucket ownerに強制するようにしてください。
最後のものは、s3 bucketのPermissions→Object Ownershipで以下のように、Bucket Owner Enforcedが指定されていることを確認してください。

詳しくは、以下を参照して欲しいのですが、 docs.aws.amazon.com repost.aws
ALB logのように、AWS側のaccountがS3 bucketにobjectを保存する形式の場合、設定によって以下のような違いが生じます。
- Object Owner Enforced
- bucket ownerのobjectとなる
- こちら側のobjectとなる
- cross accountでのGetObjectも適切にacceptする設定を行えば可能
- Object Writer
- objectを書き込んできたAWSがobjectのownerとなる
- AWSのobjectとなる
- cross accountでGetObjectしようとすると、AWS側のobjectのためこちら側で権限制御ができず、常に失敗してしまう
AWS ALB / www access log
ALB logはdefaultでは、有効になっていないと思います。が、アクセス元のIP addressや、status code、processing timeのような解析に非常に役に立つ情報が含まれています。まずは、有効化しましょう。 docs.aws.amazon.com
AWS managedのserviceであれば、ほぼ間違いなくAthenaを用いたログの解析が簡単に行えます。 例えば、ALBの場合も、tableを作成してqueryを投げるだけです。 詳しくは、以下を参照してください。 docs.aws.amazon.com
ALB logには、GET requestのquery parameterは記載されますが、POSTやPUT requestのbodyは記載されません。必要に応じてapplication logに出力するようにしましょう。
AWS WAF
AWS ALBには、AWS WAFを設定可能です。AWS managed ruleを利用することで簡単に運用を始めることができますが、BLOCKを行わずログを取るだけのCOUNTでruleの動作確認を行うためにもログの設定は必須です。
2021-11-15以前は、Kinesis Data Firebaseを経由する必要がありましたが、今は直接S3やCloudWatchへの出力が可能になっています。 aws.amazon.com
以下を参考にS3へWAF logを出力するように設定を行っておきます。 docs.aws.amazon.com
WAF logをAthenaで解析する場合は、以下を参照してください。 docs.aws.amazon.com
AthenaでCOUNTのログを抽出する場合は、少しクセがあるので以下の記事のqueryを参照してください。 aws.amazon.com
syslog / application log
EC2 instance 内のlogは、fluentdのs3 pluginを用いてS3 bucketに出力しておきます。 github.com
上記のlink先のexampleだと、AWS_KEY_IDやSECRET_KEYを指定して認証を行っていますが、IAM Userにはアクセス元の特定が難しい、revokeしない限り永遠に使えるなど、security的にヨワヨワなので、productionでは使いたくありません。
EC2 instance profileを用いてEC2 instanceに対して出力先のbucket/prefixに対する書き込み権限を与えておきます。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "s3:ListBucket", "Resource": "arn:aws:s3:::example-log-bucket" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject" ], "Resource": "arn:aws:s3:::example-log-bucket/*" } ] }
fluentdをinstallし、gem install fluent-plugin-s3でs3 pluginをinstallしてください。
/var/log/syslogや/var/log/auth.logをs3://example-log-bucket/syslog/... に保存する場合は以下のような設定を行います。
/etc/td-agent/conf.d/syslog.conf
<source> @type tail path /var/log/syslog pos_file /var/log/td-agent/.syslog.pos tag syslog.syslog <parse> @type syslog keep_time_key true </parse> </source> <source> @type tail path /var/log/auth.log pos_file /var/log/td-agent/.authlog.pos tag syslog.authlog <parse> @type syslog keep_time_key true </parse> </source> <match syslog.**> @type s3 s3_region ap-northeast-1 s3_bucket example-log-bucket s3_object_key_format %{path}%{time_slice}_%{index}.%{file_extension} path syslog/${tag[1]}/%Y/%m/%d/ output_time false <buffer tag,time> @type file path /var/log/td_agent/buffer/s3_${tag} timekey 300 timekey_wait 60 timekey_use_utc true flush_at_shutdown true </buffer> <format> @type json </format> </match>
nginxも以下のようにsourceのformat指定とpathを読み変えるだけです。
/etc/td-agent/conf.d/nginx.conf
<source> @type tail path /var/log/nginx/access_log pos_file /var/log/td-agent/.nginx.pos tag nginx.access_log <parse> @type nginx keep_time_key true </parse> </source> <match syslog.**> @type s3 s3_region ap-northeast-1 s3_bucket example-log-bucket s3_object_key_format %{path}%{time_slice}_%{index}.%{file_extension} path nginx/${tag[1]}/%Y/%m/%d/ output_time false <buffer tag,time> @type file path /var/log/td_agent/buffer/s3_${tag} timekey 300 timekey_wait 60 timekey_use_utc true flush_at_shutdown true </buffer> <format> @type json </format> </match>
sourceのparse formatに指定可能なものには限りがありますが、pluginを探せば大抵見つかります。 もちろん、formatが決まっているのであれば正規表現で解析できますし、jsonであれば後で何とでもなります。 でも、rails logやcatalina logのようにvariationが多いものは厳しいです。
outputする際のformatは、jsonにしておくと後が楽になると思います。
access log
ALB配下のEC2 instance内でapacheやnginxが動作している場合、ALBでTCP sessionがterminateされてしまうため、EC2 instanceから見るとALBのIP addressから接続が行われているように見えてしまいます。
このため、apacheの場合はmod_remoteip、nginxの場合はreadip moduleを利用して、X-Forwarded-Forに記載されているALBにアクセスしてきたclientのIP addressをログを記載するようにしておきましょう。
CloudTrail / audit log
CloudTrailは、AWS APIのaccess logであり、audit logです。
証跡を作成 = s3 bucketへのCloudTrail logの保存を以下に従って行っておきましょう。 docs.aws.amazon.com
EKSを利用したsystemでログを保存する
EC2 instanceを卒業したら向かう先は、ECSやLambdaでのserverlessな世界か、kubernetesなEKSの2択だと思いますが、freeeはEKSを選択しました。

kubectl logs
kubernetes cluster上のpodが標準出力に出力した内容は、kubectl logsで確認することができます。
しかし、このログはpodやnodeが入れ替わると消えてしまいます。 EKSのworker nodeの上で動くpodはAWS managedではないので、podが出力するlogは別途設定を行なってS3 bucketに退避する必要があります。
application log
そこで、kubernetes上にside carとしてfluentdを動作させたり、
daemonsetとしてfluentdを動作させて、
S3 bucketにapplication logを保存しておきましょう。
EKS Audit Log
EKS control planeはAWS managedなresourceなので、AWSが提供するaudit logを有効化しておきます。特にAPI serverのlogが重要です。 docs.aws.amazon.com
有効化すると、CloudWatch LogGroup /aws/eks/${cluster name}/cluster にlogが出力されます。
CloudWatch Logs
ECS、LambdaのようにdefaultでCloudWatch Logsが有効になるものもありますが、今回は先ほど紹介したEKS audit logを見てみたいと思います。
Log Streamの右上にあるSearch all log streamsをクリックし、queryに以下を入力することで、
{$.user.username != "eks:*" && $.user.username != "system:*" && $.requestURI = "/api/v1*"}
以下のようにsystemではなく人が実行したlogを検索できます。
{ "kind": "Event", "apiVersion": "audit.k8s.io/v1", "level": "RequestResponse", "auditID": "ad88T77b-b447-4150-bbe1-hogehoge", "stage": "ResponseComplete", "requestURI": "/api/v1/namespaces/example/pods/example-hogehoge/exec?command=%2Fbin%2Fbash&container=console&stdin=true&stdout=true&tty=true", "verb": "create", "user": { "username": "eks-operator:username-example-com", "uid": "aws-iam-authenticator:012345678912:XXXXX", "groups": [ "example-console", "system:authenticated" ], "extra": { "accessKeyId": [ "ASIAXXXXXXXXXXXXXX" ], "arn": [ "arn:aws:sts::012345678912:assumed-role/eks-operator/username@example.com" ], ... } }, "sourceIPs": [ "172.18.0.0" ], "userAgent": "kubectl/v1.21.0 (linux/amd64) kubernetes", "objectRef": { "resource": "pods", "namespace": "example-console", "name": "example-console-hogehoge", "apiVersion": "v1", "subresource": "exec" }, "responseStatus": { "metadata": {}, "code": 101 }, "requestReceivedTimestamp": "2023-02-28T11:12:16.654160Z", "stageTimestamp": "2023-02-28T11:42:25.237314Z", ... }
kubectl execで実行したcommandが/bin/shであることや、作業対象のnamespace、実行者のusername、arnなどがわかります。 kubernetes resourceに対して何らかの操作を行った場合、必ずEKS audit logに記載されます。
ただし、kubectl exec で /bin/sh でpodに入った後に実行したcommandやその出力、console logについてはEKS audit logには記録されません。
Session Manager 経由でpodにアクセスしているのであれば、console logを取れそうに見えますが、
実は、S3を出力先にしているとconsole logは取れません。別途、console logを取得する仕組みを用意する必要があります。
CloudWatch Insights
先ほどSearch all log streamで実行したqueryは、awscliだと以下のように書けます。
#!/bin/bash # date -j -f "%Y-%m-%d %H:%M:%S" "2023-12-23 10:00:00" +%s date=${1:-$(date +%s)} timestamp=$((date - date % 3600)) for t in $(seq 0 23); do end_time=${timestamp} start_time=$((timestamp-3600)) date -r ${start_time} response=$(aws logs start-query \ --log-group-name '/aws/eks/cluster-name/cluster' \ --start-time ${start_time} \ --end-time ${end_time} \ --query-string 'filter requestURI like /^\/api\/v1/ | filter user.username not like /system:/ | filter user.username not like /eks:/ | fields @timestamp, @message | sort @timestamp asc' ) query_id=$(echo ${response} | jq -rM .queryId) while [ 1 ]; do sleep 2 aws logs get-query-results --query-id ${query_id} > results-${timestamp}.json status=$(jq -rM .status results-${timestamp}.json) if [ "${status}" = "Complete" ]; then break fi echo -n . done timestamp=$((timestamp-3600)) done
引数に何も指定しなければ、1時間毎にCloudWatch Insightsで検索を行う処理を24時間分繰り返します。
CloudWatch Logs を S3に export
CloudWatch Logsは便利なのですが保管料金がS3よりも高いので、古いものについてはS3 bucketにexportしておいた方が良いです。
元々、Kinesis Data FIrehoseで行う方法が提供されていましたが、
最近、EventBridge Schedulerを用いて行う方法も提供されました。
しかし、後者は日付でprefixを分ける事ができないので、しばらくFirehoseで頑張った方が良さそうです。そのうち、updateされると期待しています。
CloudTrail / data event
CloudTrailは、defaultの状態だとmanagement eventの記録だけが行われます。 S3 bucketどのobjectに誰がどこからアクセスしてきたのかについては記録されません。
以下を参考に、data eventの記録を有効にしておきましょう。 docs.aws.amazon.com
同じaccount内にCloudTrailの出力先bucketが存在する場合に、全てのbucketについてdata eventを有効にするとdata eventの記録が暴発してしまうので、個別で有効化しましょう。
east-west、および、egress方向のログ

ここまでは、internetからserviceに向かってくる方向のlogを扱ってきました。 本当は、AWS account内部の動き=east-west方向を記録するVPC flow log、AWS accountからinternetに出ていくegress 方向のDNS resolver query log、Network Firewall log、なども触れておきたかったのですが、時間切れです。
最後に
どうでしょう? ここまでログを集めていれば、もしもの時もどこかに手掛かりが残っているのではないでしょうか? そうであってほしいww
でも、ここまでのログを集めたとして、解析大変ですよね。
障害対応のために特定の期間に限って解析するのであれば、aws s3 sync s3://example-log-bucket/hogehoge/YYYY/MM/DD . で手元に持ってきて、find . -type f -name '*.gz' | xargs gzip -dc | grep keyword で探すのでも良いのかもしれません。
でも、同じ事象を別の期間、別のサービスに水平展開するとなると辛いです。
ということで、OpenSearch上でSIEMを構築することをお勧めしておきます。 github.com ALB、WAF、application logをアクセス元のIP addressで串刺しできるだけで、解析はとても楽になると思います。
明日はkannoさんが、AWS region移行について語ってくれます!